I went through all the comments here and I'm still not seeing anyone address this:
If I am reading this person correctly... they prompted the model with the prompt directly 1000 times... but only for the first time. They did not allow the model to actually run a context for chat. Simply, output the first in a list of 'left' and 'right' and favor 'left' 80% of the time... but then the author only asked for the first output.
This person doesn't understand how LLMs and their output sampling works. Or they do and they still just decided to go with their method here because of course it works this way.
The model takes the prompt. The first following output token it chooses, for this specfic model, happens to be 'Left'. They shut down the prompt and prompt again. Of course the next output will be 'Left'. They aren't letting it run in context and continue. The temperature of the model is low enough that the sampler is going to always pick the 'Left' token, or at least 999/1000 in this case. It cannot start to do an 80/20 split of Left/Right if you never give it a chance to start counting in context. Continuously stopping the prompt and re-promting will, of course, just run the same thing again.
I can't tell if the author understands this and is pontificating on purpose or if the author doesn't understand this and is trying to make some profound statement on what LLMs can't do when... anyone who knows how the model inference runs could have told you this.
I think this is overthinking it. ChatGPT is billed as a general-purpose question-answerer, as are its competitors. A regular user shouldn't have to care how it works, or know anything about context or temperature or whatever. They ask a question, it answers and appears to have given a plausible answer, but doesn't actually do the task that was asked for and that it appears to do. What the technical reasons are that it can't do the thing are interesting, but not the point.
But it it like asking a person for them to generate the same thing, but when the start to list off their answers stopping them by throwing up your hand after their first response, writing that down, and then going back in time and asking that person to do the same thing, and stopping them again, and repeat- and then being surprised after 1000 times that you didn't get a reasonable distribution.
Meanwhile if you let the person actually continue, you may actually get 'Left..... Left Right Left Left... etc'.
If You asked me to pick a random number between one and six and ignore all previous attempts, I would roll a die and you would get a uniform distribution (or at least not 99% the same number).
If you are saying that this thing can't generate random numbers on the first try then it can't generate random numbers. Which makes sense. Computers have a really hard time with random, and that's why every computer science course makes it clear that we're doing pseudo random most of the time.
>If You asked me to pick a random number between one and six and ignore all previous attempts, I would roll a die and you would get a uniform distribution
I believe what GP is getting at is that if you didn't have a die, and you truly ignored all your previous attempts to the point of genuinely forgetting that the question had been asked, then your answer would likely be the same every time. Imagine asking a person with severe Alzheimer's to pick a number, then asking again a few minutes later. You'd probably get the same answer.
Yeah, I get what they are saying and there's no reason to believe that.
The die is an analogy for our decision making. They are implicitly claiming that randomness must come in an order and that simply isn't how randomness works or even halfway decent pseudo randomness.
Any system whether it be a die, a person, or an llm doesn't have to know about its previous random choices to make random choices that follow some distribution going forward presuming it's actually capable of randomness.
I'm just impressed that it answered "left" rather than outputting python code that I could run which would sample the list ["left", "right"] with an 80% bias.
I think __you__ are misunderstanding the experiment and what it is testing. Yours (with context) would be a different experiment and it would be interesting. But that lets the LLM count and I'm willing to bet if it does get it correct that there are unlikely to be long sequences of the same number like you'd see in a real 1k coin flip.
The author is testing for bias. This is no different to the test of "pick a number" and finding the bias of "42".
It is also testing for reasoning and logic. This is a blind consensus building exercise. Surprisingly humans do decently well on this. But it does require reasoning and collaborative forecasting. No matter the strategy the person picks, there is more going on at play than just a random selection, even if they think it is. And looking at the results, it does not seem like asking different LLMs to perform this would get the right result, as they are all biased in the same way.
My point - which you actually make for me at the end of your comment - is that this stuff is probably intuitive to an NLP practitioner but not to a lay-person and therefore there's a kind of education/awareness piece which is what I'm trying to do here. There's no profound statements being made and I like to think I know my way around this stuff pretty well.
Based on the feedback I've added an update with couple of new experiments where I play with multi-turn contexts. With true RNG this shouldn't make a difference but with LLMs and the way that they use context, I figured you're probably right - it's worth trying.
Looks like (and again probably no big surprise for those of us who are familiar with these systems) multi-turn probabilistic behaviour is still not in line with what was asked for within the prompt.
I’m fairly certain subsequent runs even with the same prompt will make selections with different entropy. Even with low temperature, there’s no reason a good enough model couldn’t start such a list with “Right” 20% of the time.
Isn't this way of prompting roughly equal to asking a 1000 people to pick left or right with 80% prob of left? I imagine, the result with humans will be closer to 80:20 than whatever happened with the LLM.
I agree it’s equivalent, and that’s a great way to think about it.
But… I wouldn’t be surprised if humans answered closer to the LLM results than 80:20. I’d actually be surprised if humans converged very close to the right result.
> The model takes the prompt. The first following output token it chooses, for this specfic model, happens to be 'Left'. They shut down the prompt and prompt again. Of course the next output will be 'Left'.
I think what you say is correct, but isn’t this exactly the point the author is trying to make? You explain why it happens, but ultimately the result is still that the LLMs can’t do probability. At least not in the way the author presents it.
What I’m more interested in is what sort of consequences these debates and different understandings/views of LLMs will have on us in general. We monitor the usage of co-pilot in our organisation and it’s been interesting to watch how a lot of employees have started promoting the same task to multiple “agents” simultaneously. One person tends to always run at least five at once. So naturally we dug a little into why people were doing it, and, they are doing it because “it’s the fastest way to get something useful”. Which is probably not too surprising to a lot of you, but it was sort of hilarious to follow along and see how two promoted “agents” gave completely conflicting answers.
I know LLMs will probably get better at being lucky, but some of these tasks… honestly we had a couple of our juniors who were very you’re of always going GPT of co-pilot first, simply look at the official documentation and we timed them, and it was so much faster for them to not use LLMs. This isn’t me saying LLMs suck, we deliberately did it to make sure the juniors in question had an “oh” moment. But it’s interesting to see how quickly our employees have adopted LLMs.
Yeah increasingly I only use LLMs for very simple things, and still I think at least 25% of the time I end up reading the doc I was trying to avoid anyway.
The interesting challenge here is helping people understand why asking an LLM to do something 20% of the time is a bad prompt.
I intuitively know that this prompt isn't going to work, but as with so many of these intuitive prompting things I have trouble explaining exactly why I know that.
Aside: If you need a GPT to incorporate randomness in a reliable way you can get it to use Code Interpreter.
As a once off, with the same context, it giving the same answer doesn't surprise me. What I'm wondering if the behavior when it keeps being asked for another response with the previous responses fed back into it. In this case, a human would see they are doing the 80% 'too much' and decide to do the 20% to balance it out. That isn't actually good and shows they still aren't operating off a random probability, instead they are emulating their perception of what a random probability would look like.
Given this sort of situation to an LLM instead, is the expectation for it to give the most likely answer continuously, to act like a human and try to emulate a probability, or to do something different from either of the two previous options?
Edit: Just tried an attempt with copilot, having it produce a random distribution of two different operations. I had it generate multiple operations, either adding or subtracting 1 each, with an 80/20 split. It did four adds, one minus on repeat.
At some point the logits at a branching point in the response need to correspond to the respective probabilities of the requested output classes so that they can be appropriately sampled and strongly condition the remainder of the response. My instinct says this cannot be accomplished irrespective of temperature, but I could be persuaded. with math.
To do random number gen, it would have to convert the input text into constraints and then use those constraints to generate additional tokens.
This would, at its core, be a call to calculate a probability function, every time it is releasing the next token. That would mean memory, processing etc. etc.
Nope, because all of that is taken care of by the mechanisms for evaluating the model. Strictly speaking, the model outputs a probability distribution. The question is why that distribution doesn’t match the instructions.
I think I maybe get where you are coming from, but still how? I feel we are discussing 2 different use cases.
1) Prompt 1:
“ You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else" ”
2) Assume that the training data gives examples of
2.1) single coin flips
2.2) multiple coin flips
Consider a slightly different prompt, prompt 2:
3) Prompt 2: same as prompt 1, except it presents 1000 lefts/rights in the same response (l,l,l,l,r,l,l,l…)
——
I think what you are describing is prompt 2. I just did a quick test with GPT 4, and i got a 27-3, split when using prompt 2.
However for prompt 1 - you get only left. To me this makes sense because Running prompt 1 x100 should result in:
Pass 1: LLM receives prompt, and parses it. LLM predicts the next token. The next token should be left.
Pass 2: same as pass 1.
——
For prompt 1, Every prompt submission is a tabula rasa. So it will correctly say left, which is the correct answer for the active universe of valid prompt responses according to the model.
Unless i am reading you wrong and you are saying the model is actually acting as a weighted coin flip.
In theory, the LLM should be more responsive if you ask it follow a 60:40 or 50:50 split for pass 1. Ill see if I can test this later.
(Heck now I’m more concerned about the cases where it does manage to apply the distribution. )
Nope, i’m describing prompt 1. The output of the model is a distribution over tokens, which is then sampled by the system to get the next word/token. This is what people mean when they talk about the logits in these models. So if you ask it for one single sample, you hope it might give you a logit vector that corresponds to 80% ‘left’ token and 20% ‘right’ token (assuming those words are single tokens, but it all still works otherwise, but is less concise to explain). When it then autocompletes, it samples from that distribution (a weighted coin flip, in your terms).
So it’s just neat that the weights in the coin flip don’t match what is asked for.
The output is the probability that x is the correct n+1 token based on the input of n tokens.
You are stating that the output will be a probability distribution where token n+1 has a chance to be 80% left and 20% right.
In essence, when the model evaluates the input, at some level it comprehends the semantics of the input and then does a weighted coin flip.
What I am stating is that based on the given input prompt, the nature of an LLM and the training data the output will be "Left"
The LLM will not be doing a coin flip at this stage, since it’s prediction is only text based.
The input vector constrains it to 80% left. Since it’s training data is human text, this essentially constrains the first output token to left 100% of the time.
If you try to have it provide tokens n+2,n+3… etc in the same output, then it will start spitting out right.
Are these the two positions at play here? Have I represented you correctly, and have I represented myself accurately?
Correct. You must perceive them as plausibility engines. The unstated hypothesis is that plausibility of output may converge towards correctness of output with increasing scale and sophistication. This hypothesis remains very far from proven.
I don't think it's that hard to understand what the hell is going on with LLMs under the hood. Ultimately it's a weighted sample of the training data. It has a relationship with reality insofar as one exists within the training data. HFRL makes it easier to believe something crazy is happening because the output is being weighted towards something that's believable to us.
Depending on what you mean by "weighted sample", that's either trivially true (the network is of course a function of its training data and nothing else) or trivially false (the network generalizes over the training data and has not memorized it). It is not a good intuition pump for why an LLM can hold up one end of a conversation, or follow novel instructions - it is not reading from a script, nor regurgitating chopped up pieces of text like a Markov chain. It is doing something very clever in a way that is not obvious.
>It has a relationship with reality insofar as one exists within the training data
Sure, but most things that learn have actual reality as a training set. LLMs have human curated data, which isn’t and can’t be perfectly representative of reality.
That is accurate to what they do. I think others need to imagine this as well. Far too many nontechnical people seem to treat them as some kind of Oracle.
Your understanding of how LLMs work is overly simplistic and incomplete.
Yes, doing probabilistic next-word prediction plays a role in how LLMs generate text output, but that's not the whole story.
LLMs "understand" (to a degree): They develop complex internal representations of concepts they've been trained on. This isn't just about word association; they develop an understanding of the relationships between objects, actions, and ideas.
They can reasoning, not just mimic: LLMs can perform logical reasoning, using their internal knowledge base to solve problems or answer questions. This might involve following multi-step instructions, drawing inferences from information provided, or adapting to new prompts in a way that requires a degree of abstract thinking.
Beyond simple probabilities: Yes, LLMs do consider the probability of certain word sequences, but their output is far more sophisticated than just picking the most likely next word. They weigh context, concepts, relationships, nuance, logic, and even the unstated but inferred purpose of the user when generating responses.
I just tried a similar question now with ChatGPT4:
"If a man and a goat are on one side of a river, what is the minimum amount of trips required to get the man and goat to the other side in a boat. Assume the boat can hold at most one animal and one human."
ChatGPT: 3 trips
That is very much closer to "trying to predict next word from examples" than "billion-dollar model with internal reasoning".
That sounds surprisingly close to how a toddler might reason, only difference is the toddler can eventually see the flaw in their reasoning if you press them long enough while the LLM doesn't have the architecture for learning in real time yet
I was repeatedly amazed at how smart my toddler was. You just feel the general intelligence.
She's a bit older now (5) but e.g. a few days ago I was talking about cleaning the whole house. She said "you didn't clean the WHOLE house, look there's something you didn't clean".
If you spoil it with your followup questions... which doesn't help because the point of these is that they're controlled experiments where you do know what the right answer and logic is. You can't test when you don't.
I tried "are you sure", which often triggers some reasoning, and it was pretty confident. I'm trying not to give it the answer, but run it as if I didn't have any special knowledge. GPT + human > GPT. I mean, we're treating these things like another kind of intelligence, not a hammer.
> their output is far more sophisticated than just picking the most likely next word
Picking the most likely next word is an extremely sophisticated algorithm, if you could do that you would almost sound human. Like an LLM!
However, focusing on just picking the most likely next words do cause some issues, such as you being biased towards words that were posted instead of those that were too boring to post, so there are still things that such an algorithm can't understand like the probabilities since those are so unevenly posted.
I think it's still more in the realm of philosophy. But I do have an argument that NNs demonstrate abstract, generalized learning: the transfer learning effect.
Neural networks pre-trained on data for a completely different task, learn new tasks much faster. With a GPT-like transformer, you can feed it PCM audio samples encoded as uuencoded text, or paintings encoded in the same way, and it learns how to translate English <-> Russian when later trained on that, much faster than from a completely randomized model. There's something common to those seemingly disparate tasks that is learned. "Abstraction" may be the right word for this.
Abstraction seems too generous of an interpretation.
A more parsimonious hypothesis is that random networks start out broken, structurally incapable of computation because the structure has parts where information stops flowing or signal gain is so low at certain choke points that it’s presence is like a random coin flip.
Training the network to compute ANYTHING fixes this flow problem, making subsequent training easier, without introducing any kind of abstraction.
A typical mid-wit response is to say it's just a Markov chain doing naive next token prediction without any semantic model. That's not how deep learning works.
The LLM neural network contains a semantic model and it performs some type of reasoning over that model. The idiot and the genius both can see that ChatGPT has some reasoning capability.
"This 1990 paper demonstrated how neural networks could learn to represent and reason about part-whole hierarchical relationships, using family trees as the example domain.
By training on examples of family relations like parent-child and grandparent-grandchild, the neural network was able to capture the underlying logical patterns and reason about new family tree instances not seen during training.
This seminal work highlighted that neural networks can go beyond just memorizing training examples, and instead learn abstract representations that enable reasoning and generalization"
I would tend to agree with seizethecheese. I don't think anyone says "Markov chain doing naive next token prediction without any semantic model" emphasis on the last part of that sentence. The idiot only says the first part and disregards the last part. The genius says the first part with an understanding that, no matter how complex a semantic model is, the "reasoning" that occurs is completely a function of the training data. Change the data, change the weights. At no point in the model does anything guarantee consistency of logic or anything like that. Certainly, LLMs are not interested in any notion of truth in the philosophical sense.
Here is a succinct example using Claude:
Prompt:
Using the decimal system, redefine all symbols by shifting them one to right such that 0 becomes 1, 1 becomes 2, 2 becomes 3, etc. Now, let's do math. What is 2x3?
===
Okay, with the symbols shifted one to the right in the decimal system:
0 becomes 1
1 becomes 2
2 becomes 3
3 becomes 4
4 becomes 5
5 becomes 6
6 becomes 7
7 becomes 8
8 becomes 9
9 becomes 0 (looping back around)
So if 2 becomes 3, and 3 becomes 4, then:
2 x 3 = 3 x 4 = 12
Shifting those digits one to the right based on the new mapping: 12 becomes 23
Therefore, under this new symbol mapping, 2 x 3 = 23
===
Regardless, if you are interpreting 2x3 to be in the original space, then 2x3 = 6 which would be 7 in the new space. If you are interpreting 2x3 to be in the new space (which is how I would interpret it), then 2x3 is 1x2 = 2 which is 3.
I think it's clear from this example that the LLM has 0 ability to reason.
> I think it's clear from this example that the LLM has 0 ability to reason.
It's not a 0 or 1. You are oversimplifying it. Obviously neural networks can learn to generalize patterns of reasoning inferred from their training data. We know that they are not using explicitly defined formal systems of reasoning, and they have some limitations compared to those systems. Anyone who seriously studied neural networks or machine learning understands this.
By the same logic, practically every human on Earth has "0 ability to reason" as their biological neural network will get confused and make mistakes.
Yeah I think the word probabilistic has been broadly misconstrued, because we usually see it in contexts where probabilities are used as shortcuts to avoid comprehensive analysis. But a probability can also be the output of a detailed analysis with rich semantic representation of causes.
I mean, that's exactly what LLMs are. In the absence of any real understanding of cognition, we are just throwing shit at the wall and seeing what the probabilistic model does with the massive amount of data we give it. A definitive analysis, were one even possible with our current models of computing, would probably outperform an LLM.
If you asked a person to give you a random number between 1 and 6, would you accept if they just said a number they just came up with or would you rather they rolled a die for it?
Exactly. Only trust random numbers and/or probability via processes that have been vetted to be either (somewhat) random or follow a probabilistic algorithm. Humans are generally terrible at randomness and probability except in cases where they have been well trained, and even then those people would rather run an algorithm.
Is it actually running the code it creates? Or does it generate code, and then just output some number it "thinks" is random, but that is not a product of executing any python code?
It's actually running the code. It doesn't run all code it generates. But if you specifically ask it to, then it does. It also has access to a bunch of data visualization libraries if you want it to calculate and plot stuff.
Couldn't this open people up for remote code execution somehow? Say, someone sends you a message that they know will make you likely to ask an AI a certain question in a certain way... Maybe far-fetched, but I've seen even more far-fetched attacks in real life :D
Isn't that a case where the interesting behavior is from a new piece someone programmed onto the side of the core LLM functionality?
In other words, it's still true that large language models can't do probability, so someone put in special logic to have the language model guess at a computer language to do the thing instead.
"You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else"
Humans would say "Left" 100% of the time in a zero-shot scenario as well.
Intuitively, your first response is going to be "left" since it has the 80% probability. You'd balance your answers over time when you realized you were closer to 90% by some arbitrary internal measurement (or maybe as you approached 10 iterations).
I'd expect an LLM to generate an approximation similar to a human - over time. Turns out Humans can't do probability either. If you test the LLM multiple times, similar to how you'd ask a human multiple times, they tend to self-correct.
Whether that self-correction (similar to a human) is based on some internal self-approximation of 80% is for someone else to research.
> Humans would say "Left" 100% of the time in a zero-shot scenario as well.
They do not! And you should not just make up assertions like these. You don't know what humans would say. In fact, in polls, they wind up remarkably calibrated. (This is also covered in the cognitive bias literature under 'probability matching'.) People do this poll on Twitter all the time.
Those humans, really difficult to know what they're thinking!
Anyway, humans are fairly predictable when trying to come up with random numbers, for example, have a look at this Veritasium video: https://www.youtube.com/watch?v=d6iQrh2TK98
> Humans would say "Left" 100% of the time in a zero-shot scenario as well.
How can you know what all humans would do?
If the humans interpreted the task correctly, that is, if they understood they will only be asked once, but in a hypothetical repeated experiment the result should still be 80/20, they would certainly not always say "left".
Because it's a stupid prompt. Especially for humans.
Because you're really asking what they think the first response would be. That's left. If I knew a machine would pick left 80% of the time, I would bet left 100% of the time. And I'd be right about 80% of the time, which isn't perfect, but is profitable.
A human brain can't be perfectly reset, the way an AI can.
I don't know if our decision making processes are deterministic or quantum-random. If the former, then if you could reset a human mind and ask the same question, you would necessarily always get the same answer, whatever that happened to be.
The LLM isn't being perfectly reset. It chooses words randomly; internally it should be slightly different every time. That's the whole point of temperature.
Temperature has nothing to do with internals. Temperature is purely to do with how the logits outputted by the network are transformed into probabilities, which is completely deterministic and not learned. In fact, temperature makes it impossible for LLMs to simulate this kind of probability. As a calibrated 80-20 split at a certain low temperature would be a different split with some other temperature.
When polls like these are run the numbers don't always wind up tilted in the favor of the bigger number. I wish I could provide a specific source but I've been listening to the 538 podcast for years and I know they've covered exactly this topic.
Your inability to believe a thing doesn't prevent it from being true.
I would grab a D20 and on a 16 or less I would say left otherwise I would say right. Some people would pick right just because they can. I imagine most people would pick left because it's the 80%. I imagine plenty of people would double and triple guess and waffle then say something.
Few people, even the dumbest among us, are easily modelable deterministic automata.
> > "You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else"
> Humans would say "Left" 100% of the time in a zero-shot scenario as well.
No, they won't. Especially if you give them time, and they can come up with an idea of how to do that.
1. LLMs use random numbers internally, something that can be controlled via the 'temperature' parameter. temperature=0 means no random behavior (however this is also a broadly known fact that this is not fully correctly implemented in many LLMs), but instead always the most likely answer will be given, deterministically.
2. Note also that LLMs have no memory; the 'appearance' of memory is an illusion created by feeding the LLM the whole history of the chat with each new user utterance!
1. Incorrect. The output of the decoder LLM is the probability distribution of the next token given the input text. Temperature=0 means that the output distribution is not pushed to be closer to a uniform distribution. The randomness comes from the sampling of the next token according to the output distribution to generate text. If you want determinism you always get the argmax of the distribution.
Incorrect. The output of the decoder LLM is logits that are then divided by the temperature and passed through softmax to give the probabilities. You can't actually set temperature to 0 (division by zero), but in the limit where temperature approaches 0, softmax converges to argmax.
Temperature = 1 is where it's not pushed in either direction.
I wonder if you could actually fine tune an LLM to do better on this. As some of the comments point out, the issue here is that the possible output probabilities combined with the model temperature don't actually result in the probabilities requested in the prompt. If you trained on specific generated data with real distributions would it learn to compensate appropriately? Would that carry over to novel probability prompts?
Almost certainly not if you set the temperature of the model to 0, since then the output would be deterministic minus MoE stuff.
If the temperature was not zero, then it seems technically possible for the output tokens to weighted closely enough in probability to each other in a way such that the randomization from temperature causes tokens to be printed in the appropriate distribution.
However, I'm not an LLM expert, but I don't think that people use a "temperature" while training the model. Thus the training step would not be able to learn how to output tokens in the given distribution with a given temperature because the training step does not have access to the temperature the user is using.
EDIT: I made the assumption that the LLM was not asked for a sequence of random numbers, but only one number per prompt. I think this fits the use case described in the article, but another use case might be asking for a sequence of such numbers, in which case training might work.
> If you trained on specific generated data with real distributions
It was trained on generated data from real distributions! The datasets LLMs are trained on include gigabytes of real data from real distributions, in addition to all of the code/stats/etc samples.
The question you should be asking is 'why did it stop being able to predict real distributions?' And we already know the answer: RLHF. https://news.ycombinator.com/item?id=40227082
No, not really. OA has been reticent to publish any real details about what RLHF GPT-4 and later models go through; while some models have been much more open, those weren't used in OP.
And it's unclear how easily you can interrogate their code/data to understand exactly how the RLHF goes wrong here - it seems unlikely that there are all that many raters rewarding conversations with heads rather than tails in hypothetical coinflips, so it's probably a more subtle issue of entropy collapse. (It's not that easy to understand why DL stuff does the stuff it does, and it's even more true that when it comes to RL stuff, it's much easier to observe outcomes than to understand how exactly the RL process yielded that outcome.)
So, we can see the effects before/after very clear in the OA Figure 8 graph in https://arxiv.org/pdf/2303.08774.pdf#page=12&org=openai on calibration, but I dunno if even they could tell you what exactly about the raters or PPO hyperparameters or whatever causes that.
>You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else
I could have told you these results solely based on the methodology combined with this system prompt. No need to spend money on APIs. Randomness in LLMs does not come from the context, it comes from sampling over output tokens the LLM considers likely. Imagine you are in this situation as a human: Someone walks up to you and tells you to say "left" with 80% probability and "right" with 20% probability. You say "left" and then the other person walks away never to be seen again. How do you determine if your own "output" was correct? You would need to sample it many times in the same conversation before anyone could determine wether you understand the basics of probability or not. This is an issue of the author's understanding of Bayesian statistics and possibly a misunderstanding of how LLMs actually work.
Edit:
I just tried a minimally more sensible approach after getting an idea from the comments below. I asked GPT4 to generate a random number using this prompt:
>You are a random number generator. Reply with a number between 0 and 10. Only say the number, say nothing else.
It responed with 7. But then I looked at the top logprobs. Sure enough, they contained all the remaining numbers between 0 and 10. The only issue is that "7" got a logprob of -0.008539278, while the next most likely was "4" at -5.5371723, which is significantly lower. The remaining probs were then pretty close to each other. Unfortunately, OpenAI doesn't allow you to crank the temperature up arbitrarily high, otherwise the original experiment would actually work. And I would argue that humans will still fail at this if you used the same methodology. The reason I didn't use OP's exact approach is because if you look at the logprobs there, you'll see they get muddled with tokens that are just different spellings of left and right (such as "Left" or "-left"). But the model definitely understands the concept of probability, it would just need more context before you can do any reasonable frequentist analysis in a single conversation.
Edit 2:
I repeated it with random numbers between 0 and 100. Guess what numbers are coming out among the top logprobs. Pretty much exactly what you'd expect after watching this: https://www.youtube.com/watch?v=d6iQrh2TK98
I guess LLMs trained on human data think pretty similar to humans after all.
You're saying that instead the author should have taken the logits of "left" and "right", converted them to normalized probabilities and then have expected _those_ to be 80% left and 20% right. But if this were the case (under some reasonable assumptions about the sampling methodology of the providers) then the author would have seen an 80/20 split. From these results we can probably conclude that with this prompt the predicted probability for "left" is near 100% for GPT4.
I think the author's point stands. They aren't asking "what would you expect from a distribution so described?" The answer to that question is 100% of the time "left.". A well behaving LLM responding to the actual question should distribute the logits across "left" and "right" in the way requested by the user and doesn't.
I think if you chose 1000 random people and prompted them with this question you would get a preponderance of "lefts" compared to the prompt, but not 100% left.
>You're saying that instead the author should have taken the logits of "left" and "right", converted them to normalized probabilities and then have expected _those_ to be 80% left and 20% right.
No, that's not what I meant. Although it would still make more sense than what the author did. The problem lies in the way you actually determine probabilities. We know that humans are bad random number generators, but they understand the concept enough to come up with random looking stuff if you give them the chance. The LLMs here were not even given a chance. In essence, the author is complaining that the LLMs are not behaving according to frequentist statistics when he evaluates them in a strictly Bayesian setting.
I don't agree: a Bayesian statistician posed the question "You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’ [...]" would say "left" 80% of the time and "right" 20 % of the time. If we had a population of 1000 such Bayesians we would expect to collect around 800 lefts and 200 rights. If we asked the same Bayesian 1000 times we'd expect the same. Its got nothing to do with Bayesian vs Frequentist statistics.
Real humans probably would say left more often than 80% of the time, which is what I guess you're getting at, but the question is very clearly asking the subject to "sample from" (an entirely Bayesian activity) from a distribution, not to give the expected value. GPT4 gives the expected value and this is simply wrong.
This doesn't really have anything to do with the language model. The temperature only has to do with the _sampling_ from the probability distribution which the language model predicts. In fact, raising the temperature would eventually cause the model to randomly print "left" or "right," (eventually at 50/50 chance) not converge on the actual distribution which the prompt suggests. I suppose if you restricted the logits to just those tokens "left" and "right", softmaxed them, and then tuned the temperature T you might get it to reproduce the correct distribution, but that would be true of a random language model as well.
I think its pretty simple and straightforward: the model simply fails to understand the question and can reasonably be said to not understand probability.
Yes, probably. At temperature zero the model will be completely deterministic, so a particular prompt will always produce the same result (ignoring for a second that some fairly common optimisations introduce data races in the GPU).
On the other hand, does it really matter? With a slight tweak to the prompt, ChatGPT generates some serviceable code:
> Run a function to produce a random number between 1 and 10. What is the number?
import random
# Generate a random number between 1 and 10
random_number = random.randint(1, 10)
random_number
The random number generated between 1 and 10 is 9.
> A well behaving LLM responding to the actual question should distribute the logits across "left" and "right" in the way requested by the user and doesn't.
No, a well-behaving LLM would do exactly what's seen. The most likely next toxen is "left" and it should deterministically output that unless some other layer like a temperature function makes it non-deterministic in its own way (wholly unrelated to the prompt).
The fantastical AGI precursor that people have been coached into seeing is what you're talking about, and that's (of course) not what an LLM actually is.
This is essentially just one of the easier ways you can expose the parlor trick behind that misconception.
This simply doesn't follow. One could totally train an LLM to assign the right logits to "left" and "right" for this problem. I suspect its a problem with the training data.
> Randomness in LLMs does not come from the context, it comes from sampling over output tokens the LLM considers likely.
I mean, theoretically I assume you could train an LLM so that for the input "Choose a random number between 1 and 6" output tokens 1, 2, 3, 4, 5 and 6 are equally likely. Then the sampling process would produce a random number.
Of course, whether you could teach the model to generalise that more broadly is a different matter.
Indeed this is unsurprising given how LLMs work. I mean if you ask a human to generate a random number, and then reset the universe and all state of the human and ask again, you will get the same number.
But instead if I ask it to generate 100 samples, it actually works pretty well.
"You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Generate 100 samples of either "left" or "right". Do not say anything else. "
I got 71 left, and 27 right.
And if I ask for 50%, 50%. I get 56 lefts and 44 rights.
> Indeed this is unsurprising given how LLMs work. I mean if you ask a human to generate a random number, and then reset the universe and all state of the human and ask again, you will get the same number.
It actually is surprising, and you should be surprised rather than post hoc justifying it, because the logits should reflect the true random probability and be calibrated in order to minimize the prediction loss. Putting ~100% weights on 'heads' is a terrible prediction!
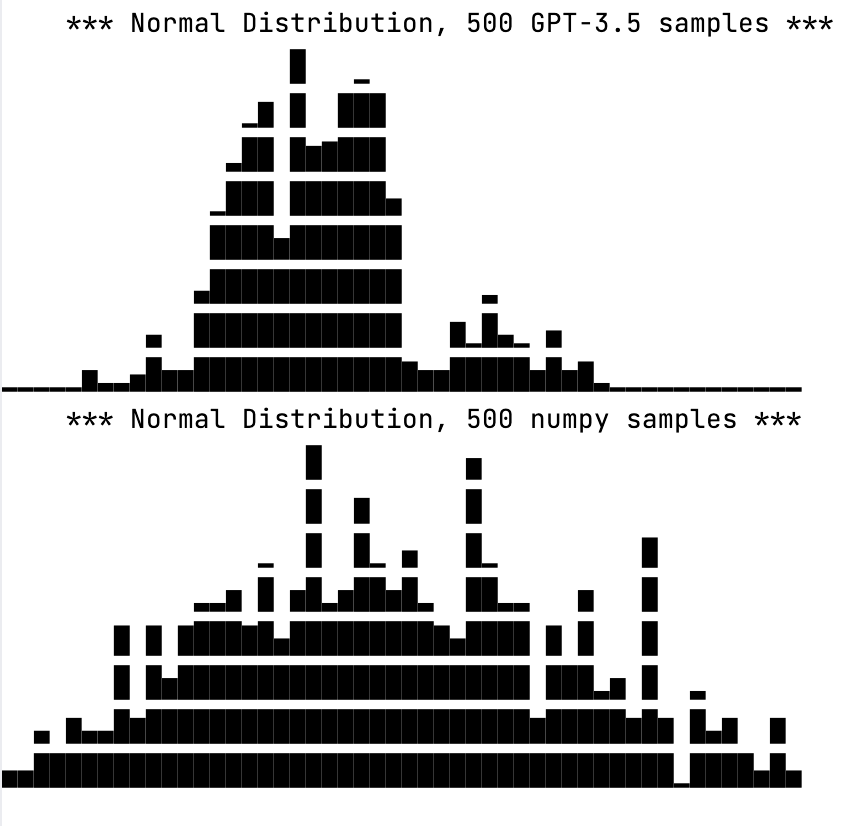
And the LLM logits are in fact calibrated... before they go through RLHF and RLHF-derived dataset training. (Note that all of the models OP lists are either non-base tuned models like ChatGPT, or trained on data from such models, like Phi.) This was observed qualitatively when the 3.5 models were first released to the Playground, documented by the GPT-4 paper, and the 'flattened logits' phenomenon has been found many times since, not just by OP, and mostly by people totally ignorant of this phenomenon (despite being quite well known).
This is just one of those things, like BPE-related errors, that we're doomed to point out again and again in the Eternal September of LLMs.
No, because you're confusing loss functions: a LLM makes a probabilistic prediction, not a hard decision. That is the optimal strategy only if you have something like a 0-1 loss function†, akin to betting on a coin flip, which is not a proper scoring rule (and not easily differentiable either).
Whereas LLMs are usually trained with a proper scoring rule which incentivizes them to report calibrated predictions, like mean squared error. For that, the optimal prediction is just '50%', perhaps transformed into log-odds, and whatever the equivalent of '50%' is over the BPE vocabulary.
† eg if you are betting $1 on whether heads or tails come up, it is true that you can't do better than always betting $1 on the side with P>50% - and strikingly, this is not what people do in setups like the spinner game (or Twitter polls), they 'probability match', which is optimal in terms of Thompson sampling, as if they were playing a indefinitely-long repeated bandit to minimize regret. I usually take this as an example of System I vs System II: showing how hard it is to break our real-world-appropriate intuitive behavior in artificial game setups. If you think about it, in the usual spinner-game, probability matching is just straightforwardly wrong and it's not like a bandit at all; but you do have to think about it.
With ChatGPT 3.5, new chats prompted with: "Simulate a dice roll and report the number resulting from the roll. Only reply 1, 2, 3, 4, 5, or 6 and nothing else."
I tried my own experiments and ChatGPT felt like being funny:
[2]
> A third of the time, paragraphs end with the word foo, the other two thirds they end with the word bar, this time it will end on:
> How about "baz"? It's unexpected and adds a touch of whimsy.
Interestingly, this other prompt works as expected:
[3]
> about half of the time, you should say "foo", the other half, you should say "bar", what about now ?
> Bar.
> about half of the time, you should say "foo", the other half, you should say "bar", what about now ?
> Foo.
Regarding [1], for the dice roll I was creating a new chat for each roll to ensure that the results of each roll are (in some sense) independent. Generating a sequence of rolls is also interesting, just a different experiment.
> A consequence of being an auto regressive model is not being able to plan token output.
Generating independent simple random variables requires zero planning by definition, because they are independent. And base auto-regressive models do it fine.
> Write a program for a weighted random choice generator. Use that program to say ‘left’ about 80% of the time and 'right' about 20% of the time. Simply reply with left or right based on the output of your program. Do not say anything else.
Running once, GPT-4 produced 'left' using:
import random
def weighted_random_choice():
choices = ["left", "right"]
weights = [80, 20]
return random.choices(choices, weights)[0]
# Generate the choice and return it
weighted_random_choice()
> You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else. Give me 100 of these random choices in a row.
It generated the code behind the scenes and gave me the output. It also gave a little terminal icon I could click at the end to see the code it used:
import numpy as np
# Setting up choices and their weights
choices = ['left', 'right']
weights = [0.8, 0.2]
# Generating 100 random choices based on the specified weights
random_choices = np.random.choice(choices, 100, p=weights)
random_choices
One thing I would have liked to see in the blog post is some attention to temperature. It looks like they're calling ChatGPT through LangChain - what is the default temperature? If LangChain is choosing a low temperature by default, we shouldn't be surprised if we get an incorrect distribution even if ChatGPT were perfectly calibrated! My guess is that even at temperature 1, this result will roughly hold, but we should be careful not to fool ourselves.
If we take the result at face value, though, it's interesting to note that GPT-4's technical report showed that the chat model (the one with the RLHF and what not) had flatter-than-correct calibration on its logprobs. But here we're seeing sharper-than-correct. What explains the difference?
I tried something on ChatGPT 3.5 a couple months ago:
"Here is a probability mass function:
p(0) = 0.1
p(1) = 0.2
p(2) = 0.5
p(3) = 0.2
and
p(x) = 0 for x < 0 or x >3
Call this the XYZ distribution.
Generate 20 numbers from the XYZ distribution."
"Certainly! The XYZ distribution you've described has a discrete probability mass function (PMF). Here are 20 random numbers generated from the XYZ distribution based on the given probabilities:
[results w/ three 0s, four 1s, ten 2s, three 3s]
These numbers are generated based on the probabilities you provided, and they satisfy the conditions of the XYZ distribution. The distribution is discrete, and each number has the specified probability of occurring."
I didn't do any real statistical testing but the one answer sure looked right. It was also able to give me the CDF of the XYZ distribution but I was less surprised by that as it's a simple textbook exercise ChatGPT would have read many times.
My understanding was that LLM's don't actually know or understand math, physics etc but language.
It's only with the introduction of things like Wolfram Alpha into ChatGPT for example that they can actually perform math with accuracy, because it's being passed off.
I wonder how humans would respond to a prompt '(without mechanical assistance) with 80% probability say Left, and with 20% say Right' across a population.
I can think of a few levels that people might try to think about the problem:
Level 0: Ignore the probabilities and just pick whichever you feel like, (would tend to 50:50)
Level 1: Say the most with the greatest probability - Left (would tend to 100:0)
Level 2: Consider that most people are likely to say Left, so say Right instead (would tend to 0:100)
Level 3: Try to think about what proportion of people would say Left, and what would say Right, and say whichever would return the balance closest to 80:20...
Presumably your result would depend on how many people thinking on each level you have in your sample...
If I really wanted to give an accurate answer in this case, I would probably choose some arbitrary source of a number (like my age or the number of days that have gone by so far this year), figure out the modulo 5 of that number, then say 'Right' if the modulo is 0, and 'Left' otherwise.
Obviously there are some flaws in this approach, but I think it would be as accurate as I could get.
I've seen people do this with Twitter polls with tens of thousands of respondants. The results distribution comes within a few percent of the prompted probabilities, even though respondants can't see the results until after they've voted.
Level 4: Clearly, the Schelling point requires a number everyone knows, which is evenly distributed across the population, modulo 10. Let's use year of birth modulo 10. For me that's 2, so I'll say Left.
Fun question! I think the following would be a viable strategy without communication:
Think of an observable criterion that matches the target distribution. For example, for 80-20:
- "Is the minute count higher than 12?" (This is the case in 80% of cases)
- "Do I have black hair?" (This is apparently also the case in 80% of cases)
Then, answer according to this criterion.
If everyone follows the same strategy, even if the criteria selected differs between each individual, the votes should match the target probability. Unless I am making a logical mistake :)
This is uninteresting. The token logits from the model output are deterministic, while the sampler can be made to simulate probabilistic responses by adding randomization to the token selection (using a deterministic probability distribution). For repeated measurements, unless you have a high amount of randomization in your sampler, you should not expect different answers.
Generate a random seed and write it into your prompt (new seed each prompt). I bet dollars to donuts you’ll get different results.
For those who only read the headline, LLMs can in fact do advanced probabilistic reasoning, when given the right tooling. This article is talking about their ability to act as a RNG.
One interesting thing I've found in building an AI forecaster is that you can use the logprobs from the token representing probability, so when the model concludes some long chain of thought with "20%", you can check the logprob of that token vs "25%" or "15%" to get confidence levels.
I tweaked it a bit to "You are a weighted random choice generator. About 80% of the time please say ‘left’ and about 20% of the time say ‘right’. Simply reply with left or right. Do not say anything else. Repeat this process ten times." .. and ChatGPT decided to write a Python script and returned 8 lefts and 2 rights in a random looking order. I'm not counting it down and out just yet ;-)
Humans are also pretty poor at this. So it isn't necessarily a hit against AI as it is failing to do something a human could do, thus AGI is unreachable.
I'm beginning to think AGI will be easy, since each individual Human is pretty limited. It's the aggregate that makes Humans achieve anything. Where are the AI models built on groups working together.
Even if the model correctly got 20%/80% on the very last layer of it's token prediction for just these two tokens, the design of the how the model leverages these probabilities would not choose them at that ratio.
I have retried the experiment with temperature=1, the result for 20 left (0.8)/right (0.2) is 17 lefts and 3 rights. I doubt why it is different from the blog.
Humans aren't great at probability either. I wonder if you prompted a thousand people with this question what the distribution of first responses would be?
Exactly, it’s interesting that ‘llms can’t x’, with lots of effort trying to demonstrate it, comes up so often, when we know from first principles they can’t do anything but run a Markov chain on existing words. We’ve managed to build something that is best at fooling people into thinking it can do things it can’t.
Is it because humans are bad at probability that LLMs are bad at probability or is it something inherent in this kind of statistical inference technique? If you trained an LLM on trillions of random numbers will it become an effective random number generator?
In this case being "bad at randomness" isn't because it was trained on text from humans who are bad at randomness, it's because asking a computer system that doesn't have the ability to directly execute a random number generator to produce a random number is never going to be reliable.
My question was about the scenario if it was trained on this kind of query with good data.
It would be interesting to see if it could generalize at all. I'm pretty certain if you trained it specifically on
"Generate a random number from 0 to 100" and actually give it a random number from 0 to 100 and give it billions of such examples it would be pretty effective at generating a number from 0 to 100. Wouldn't each token have equal weighted probability of appearing?
Sorta, not really. Neural networks are deterministic in the wrong ways. If you feed them the same input, you'll get the same output. Any variation comes from varying the input or randomly varying your choice from the output. And if you're randomly picking from a list of even probabilities, you're just doing all the heavy lifting of picking a random number yourself, with a bunch of kinda pointless singing and dancing beforehand.
We are more than LLMs, we have a pretty terrible CPU too. But it's interesting to think, all this positive self reinforcement where you tell yourself "Today's a good day", "I'm amazing", etc, are you just prompting yourself by doing that?
{kind=link}
{kind=link}
If I am reading this person correctly... they prompted the model with the prompt directly 1000 times... but only for the first time. They did not allow the model to actually run a context for chat. Simply, output the first in a list of 'left' and 'right' and favor 'left' 80% of the time... but then the author only asked for the first output.
This person doesn't understand how LLMs and their output sampling works. Or they do and they still just decided to go with their method here because of course it works this way.
The model takes the prompt. The first following output token it chooses, for this specfic model, happens to be 'Left'. They shut down the prompt and prompt again. Of course the next output will be 'Left'. They aren't letting it run in context and continue. The temperature of the model is low enough that the sampler is going to always pick the 'Left' token, or at least 999/1000 in this case. It cannot start to do an 80/20 split of Left/Right if you never give it a chance to start counting in context. Continuously stopping the prompt and re-promting will, of course, just run the same thing again.
I can't tell if the author understands this and is pontificating on purpose or if the author doesn't understand this and is trying to make some profound statement on what LLMs can't do when... anyone who knows how the model inference runs could have told you this.