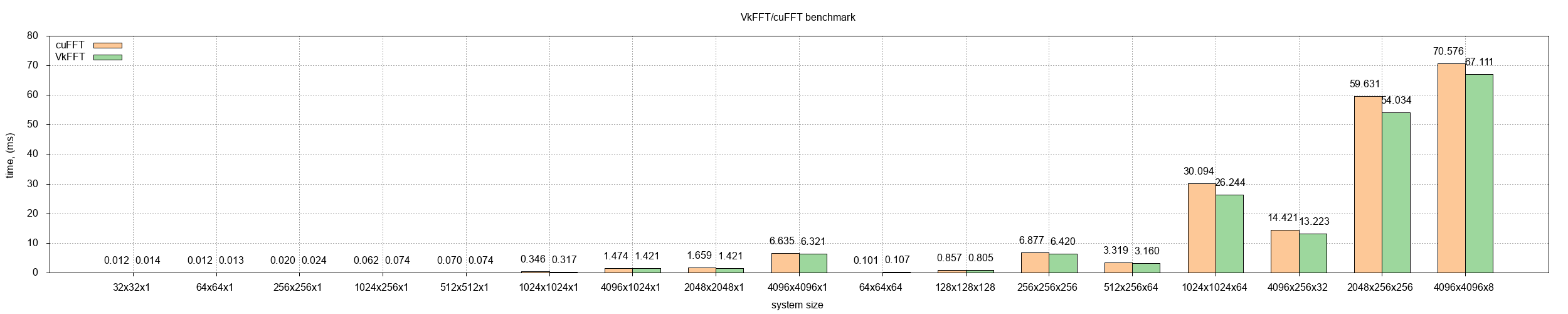
| Hello! Since the last post VkFFT has experienced a number of huge improvements and optimizations. Namely: -It now supports sequences up to 2^32 in all dimensions (algorithmically, in reality limited to allocatable memory size, switch to 64-bit addressing scheme is planned for future release) -configurations optimized for bigger range of systems and vendors -benchmarked Radeon VII and RTX 3080, shows that FFT is extremely bandwidth limited on modern GPUs -VkFFT is able to match and outperform cuFFT on the whole tested range from 2^7 to 2^28 in single precision -added double and half precision support and precision tests against FFTW on CPU -improved native zeropadding - up to 3x performance boost -switched license to MPL 2.0 Thanks for your attention! I am happy to answer any questions. |
{kind=link}
What is your explanation for this?
Is the VkFFT algorithm better? Is SPIR-V fundamentally more expressive than PTX? Are nVidia drivers better at compiling SPIR-V than PTX?
Have you compared the generated GPU assembly from both?