|
|
|
|
|
|
by DTolm
2043 days ago
|
|
|
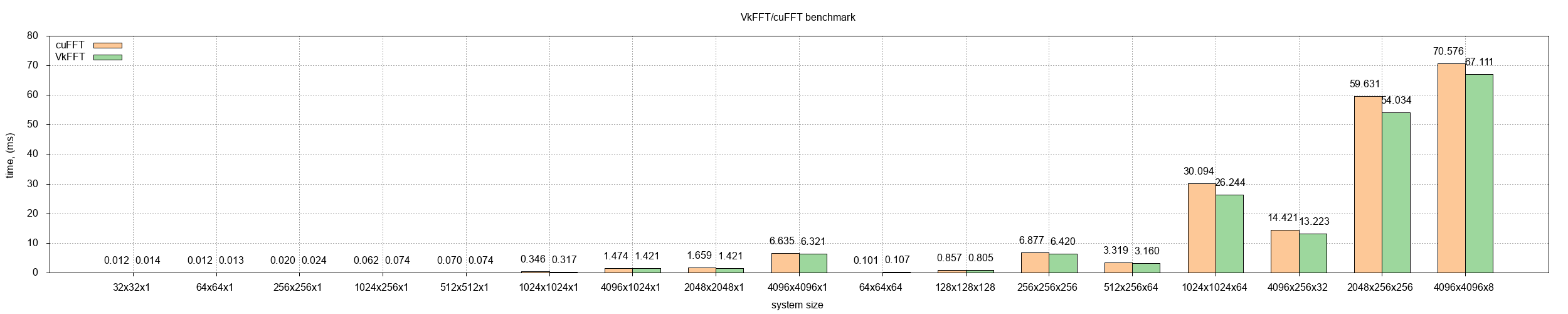
1k FFT size in single precision is 1024 x 2 x sizeof(float) = 8KB. If we don't think that it won't utilize full GPU (not even one compute unit) and assume that it scales similarly to big systems then:
1)165GB/s is an algorithmic bandwidth of benchmark, including consecutive FFT+iFFT. Both of them take one upload and one download from chip - total 4 memory transfers. The real bandwidth for this value will be 4*165=660GB/s.
2)one FFT is 2 transfers - upload and download. Total 16KB.
3)660GB/s / 16KB = 43M iterations per second. Similar to your number, but your number didn't account that benchmark has 4 uploads instead of 2. These benchmarks don't include transfers to and from GPU, as those are done with PCI-E bandwidth (30GB/s) which is really slow compared to VRAM-chip bandwidth (>500GB/s). This is why it is important to have enough VRAM and avoid CPU communications as much as possible. |
|
|
{kind=link}
https://github.com/kevinacahalan/piano_waterfall
With his motherboard it was impossible to keep both FFT views scrolling at full speed if they were large. He ended up creating a circular buffer in video memory so that he would be able to reduce the PCIe traffic to just the fresh new edge of the data. The fix doesn't work everywhere. Virtualization seems to break it, including with a Chromebook.
Is VkFFT a reasonable tool for attacking this problem? How difficult might it be to get the FFT result into the needed color component, gamma corrected and scaled, with all the other components?