|
|
|
|
|
|
by stagger87
2041 days ago
|
|
|
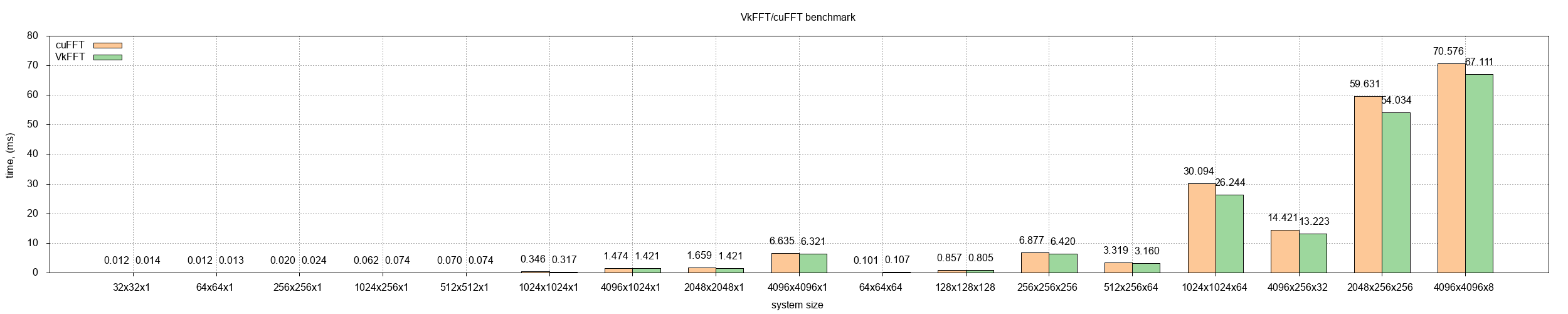
Do I understand your benchmark plots correctly? Using the single precision at 1k FFT size as my example. ~165,000 kB/ms performance Converts to 165,000 MB/s performance Divide by 8 to convert to complex samples, so 20,625 M complex samples per second. Divide by 1k to get FFT count of ~20.14M FFT/IFFTs per second? These benchmarks also include transfer time to and from the GPU? |
|
|
{kind=link}
These benchmarks don't include transfers to and from GPU, as those are done with PCI-E bandwidth (30GB/s) which is really slow compared to VRAM-chip bandwidth (>500GB/s). This is why it is important to have enough VRAM and avoid CPU communications as much as possible.