|
|
|
|
|
|
by DTolm
2037 days ago
|
|
|
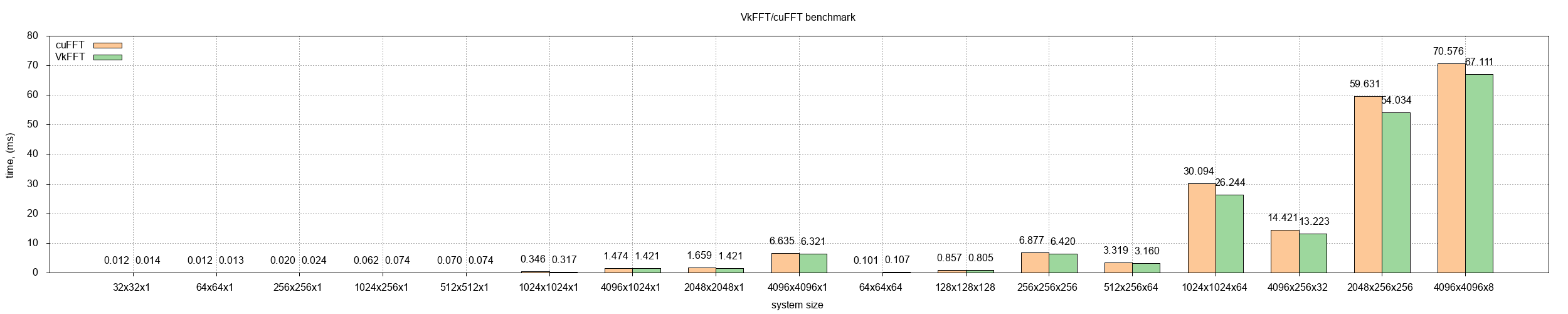
Big 1D FFTs also take a lot of memory by themselves (i.e. 2^28 takes 2GB just to store complex data). Multiple smaller batches can be used in ML applications for example for big kernel convolutions. All learning can actually be done without transferring data to CPU. In computational physics iterative processes or PDE integrators can do their algorithms independently of the CPU. About using simple time per iteration as a benchmark. I used to have this type of benchmark before the last update (see: https://raw.githubusercontent.com/DTolm/VkFFT/f7c8c45717006c...). As you can see, it is not really that informative, as you can't really compare smaller times to big ones here. The layout I use now doesn't make any assumptions about algorithm yet still provides very informative scaling - just by looking at it it is possible to jusge wether techinques like register overutilization actually work. Another important thing is that it can clearly prove that the problem is bandwidth bound and compare at which size VkFFT/cuFFT swwitch from 1 to 2 and then to 3 stage FFT algorithm. It also allows to detect wether algorithm deviates from predicted result. |
|
|
{kind=link}