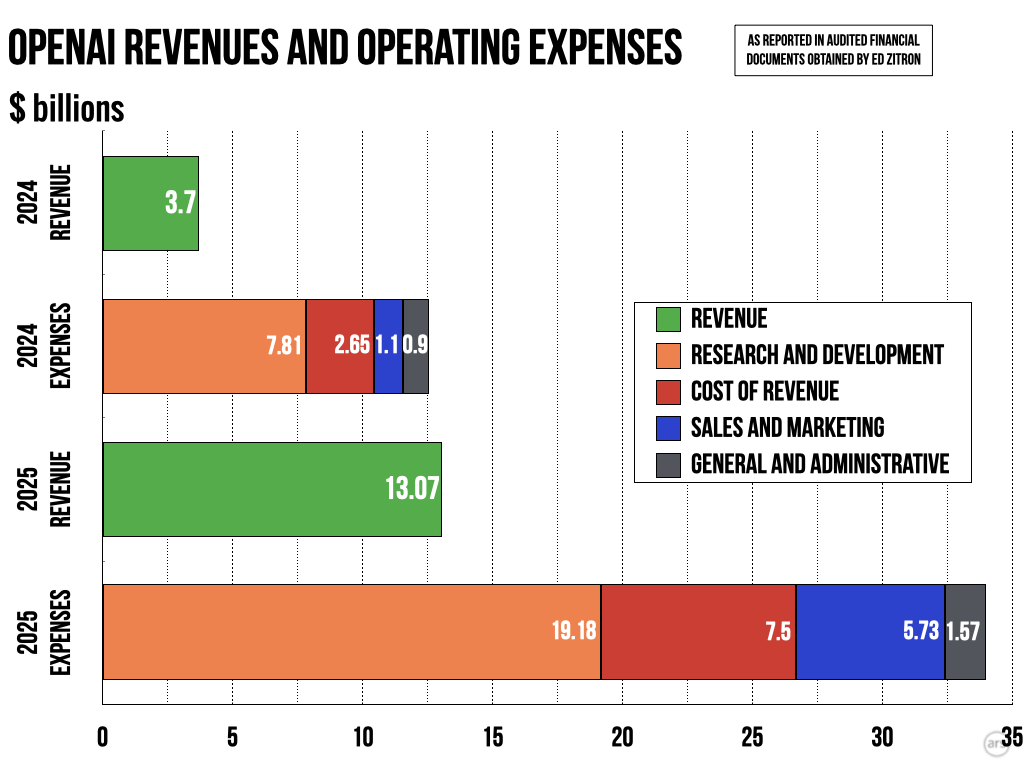
| The problem space has a few aspects: 1. We're still in the "$5 airport Uber" era of LLMs. They're heavily subsidized, and everyone still complains about costs. 2. There hasn't been a real incentive to work on cost optimization for data centers and the hardware they contain. When/if price hikes happen and send people scrambling to use other models or drastically reduce AI usage, this will suddenly need to happen. 3. We're massively overusing SOTA models. As long as you're on a subsidized subscription, you can use Claude Opus 4.8 high to write blog article meta descriptions. If you paid by token, you wouldn't do that. 4. Open models are a wildcard that could completely change the calculus. |
{kind=link}
This idea that the subscriptions are subsidized is repeated over and over, but I've never seen any proof of this. It seems to be entirely based on the inferred API cost the subscription usage could give you, but there are a lot of assumptions needed for that to follow.