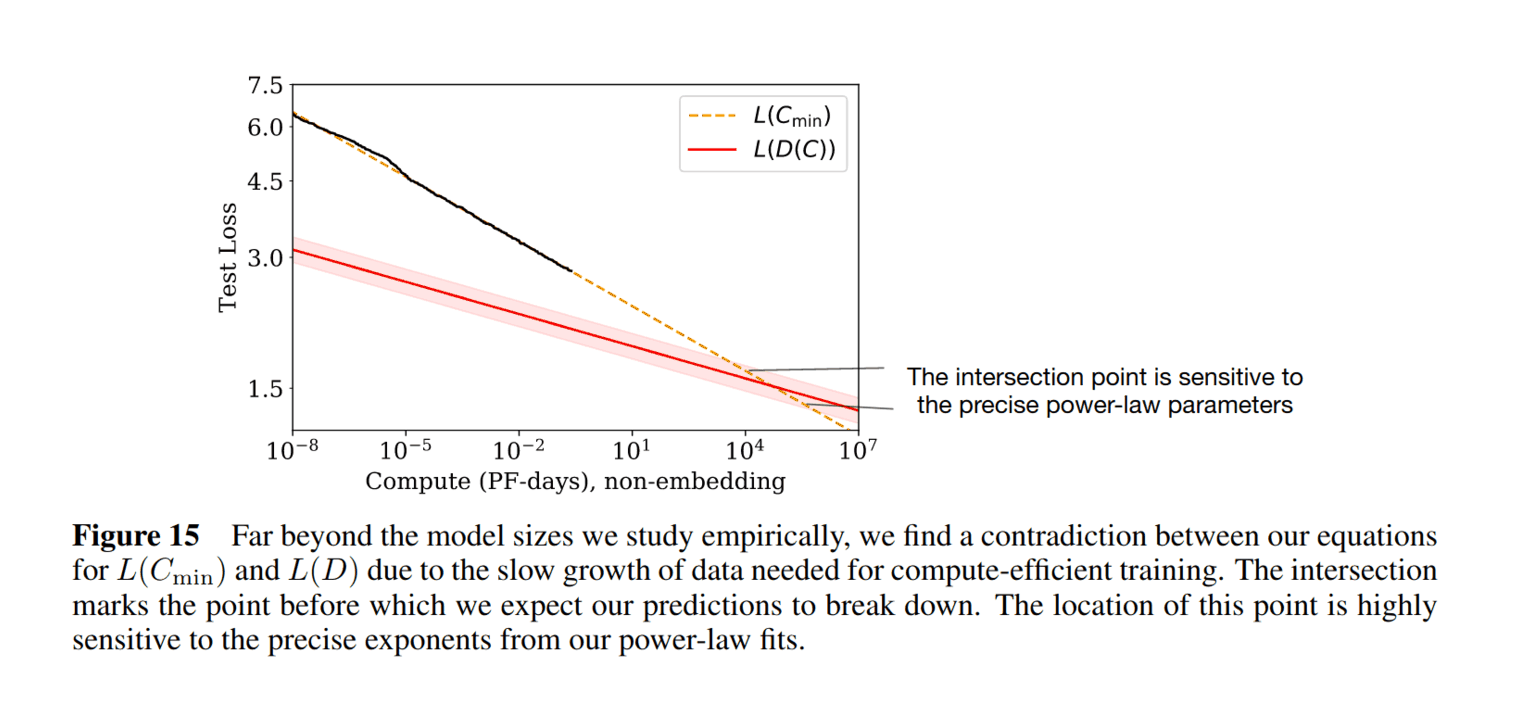
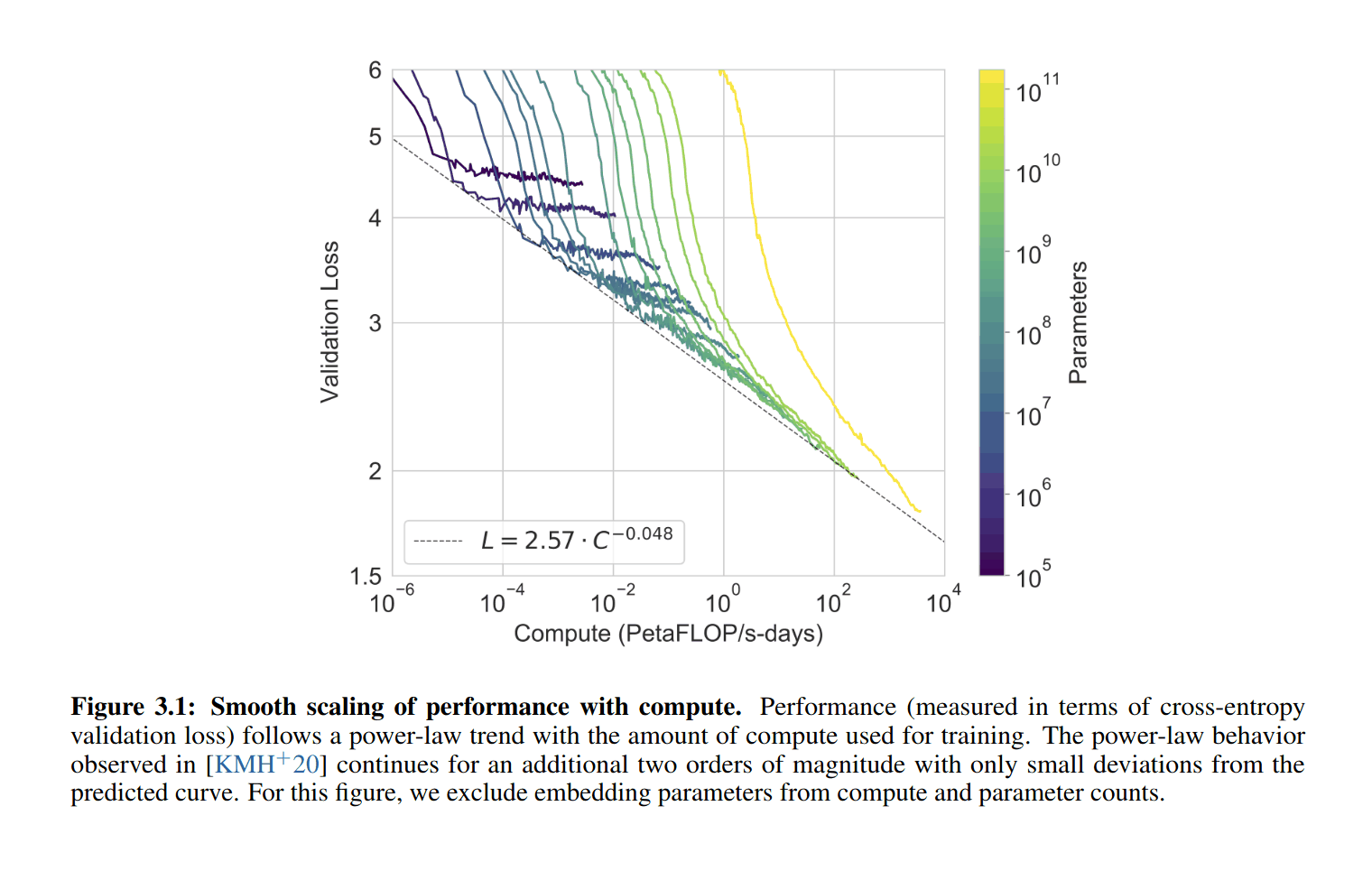
|
One fundamental challenge to me is that if each training run because more and more expensive, the time it takes it to learn what works/doesn't work widens. Half a billion dollars for training a model is already nuts, but if it takes 100 iterations to perfect it, you've cumulatively spent 50 billion dollars... Smaller models may actually be where rapid innovation continues simply because of tighter feedback loops. O3 may be an example of this. |
{kind=link}
{kind=link}
[1] https://hypertextbook.com/facts/2001/JacquelineLing.shtml