|
|
|
|
|
|
by uis
878 days ago
|
|
|
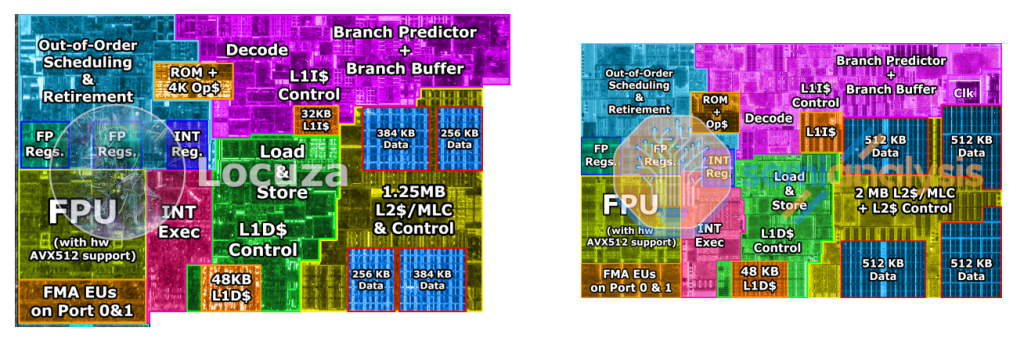
Read EDIT first. But why not just do branch delay? Or some sort of prepared branches like on ELBRUS where you can write to predicate register many instrucions ago and take conditional branch at same cost of non-conditional or maybe even prefetch intstructions into second copy of front-end like E2K does. Or some sort of explicit branch slots. Anyway, I registered here just to reply to you. I kinda want to talk to you more because you do what is interesting for me too. EDIT: I see you already store "predicates" in registers. |
|
|
{kind=link}
I get the impression that many people massively underestimate how powerful branch prediction is. Even a simple 2 bit saturating counter will correctly predict about 90% of branches, and the accuracy only goes up with better designs.
So why optimise for the uncommon case of incorrectly predicted branches? In the worst case with static branch delay slots, it actually harms branch prediction, because instead of executing the correctly predicted instructions, it's executing the delay slot, which is often a nop because the compiler couldn't find something to put there.
With your other ideas (multiple decoders, explicit delay slots) it's just a question about if it's a good use of resources (design time, transistors, compiler support) to support this uncommon case, or if you might be better off optimising something else like the branch predictor so more code goes down the common path, or just improving the pipeline's throughput in general.