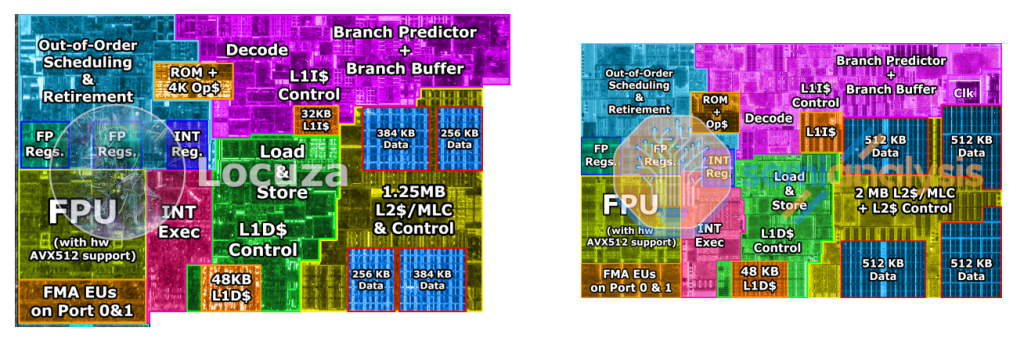
| > Single-length instructions, for example. Even x86 instructions aren't much of a problem when you can afford to throw more pipeline stages at the problem I think that the problem is bigger than that. Sure, the branch predictor usually keeps even the x86 pipeline busy, but x86 variable length instruction encoding becomes a problem for at least three problems: 1. Decoding width - There is a practical limit to how many instructions you can decode in parallell. You can add pipeline steps, but at some point it becomes absurd. 2. You get a very big range of minimum-to-maximum number of bytes that you need to fetch to extract a fixed number of instructions each clock. E.g. an eight-wide front-end would have to fetch 8-120 bytes per clock cycle. And it gets worse since your next eight instructions may not start on a nice power-of-two boundary, so you have to fetch much more, e.g. 256 bytes per cycle, in order to cover the worst case scenario (compared 32 bytes per cycle for a fixed width 32-bit RISC encoding). And you may gate cache line / page crossings in your "bundle". 3. Since you need to do fairly heavy translation work into an internal RISC-like encoding (which, by the way can not be as compact as compiler-generated RISC instructions - you typically need 64 bits per internal instruction or similar), you need to cache your translations into a uOP cache (or L0 cache). This cache uses much more silicon per effective instruction than a regular L1I cache, so it can not hold as many instructions (and I'm pretty sure that most of the instructions in the L0 cache are stored in the L1 cache too - so not really extra cache memory). All this silicon could be used for a larger L1I cache, for instance (or a better branch predictor). So, yes, branch prediction really helps, but it does not solve all problems. |
{kind=link}
{kind=link}
Branches. Branches also make really wide decodes useless. The cost/benefit is towards wider decoders for A64 than for AMD64. The average A64 instruction does slightly less work than the average AMD64 instruction so the net result is that it makes sense to have slightly wider decoders (in terms of "work") for A64 than for AMD64.
X86 CPUs don't quite use a "RISC-like encoding". The µops support RMW for memory, for example. The encoding is of course very much regularized, but I don't think the RISC people have a patent on that.
Translation to an internal format is common for high-performance RISC CPUs as well. The Power CPUs call it "cracking" when complicated instructions are split into simpler µops.