|
|
|
|
|
|
by fauigerzigerk
3715 days ago
|
|
|
>You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1). For what percentile of collections? I'm not wasting my time with incessant GC tuning only to delay that 5 minute stop the world pause for a bit longer. It's still going to hit eventually. For projects that might grow into that sort of heap size I use C++ (with an eye on Rust for the future). You are right that Go is not a panacea for very large memory situations, but you can do a lot more before Go even needs that amount of memory. The point is that languages without value types, such as Java and JavaScript, waste a huge amount of memory and generate a lot more garbage, thereby exacerbating all other related issues, including GC. I have done quite a lot of testing for our workloads. Java memory usage is consistently two to three times higher than that of Go or C++. I'm unwilling to waste our money on that. |
|
|
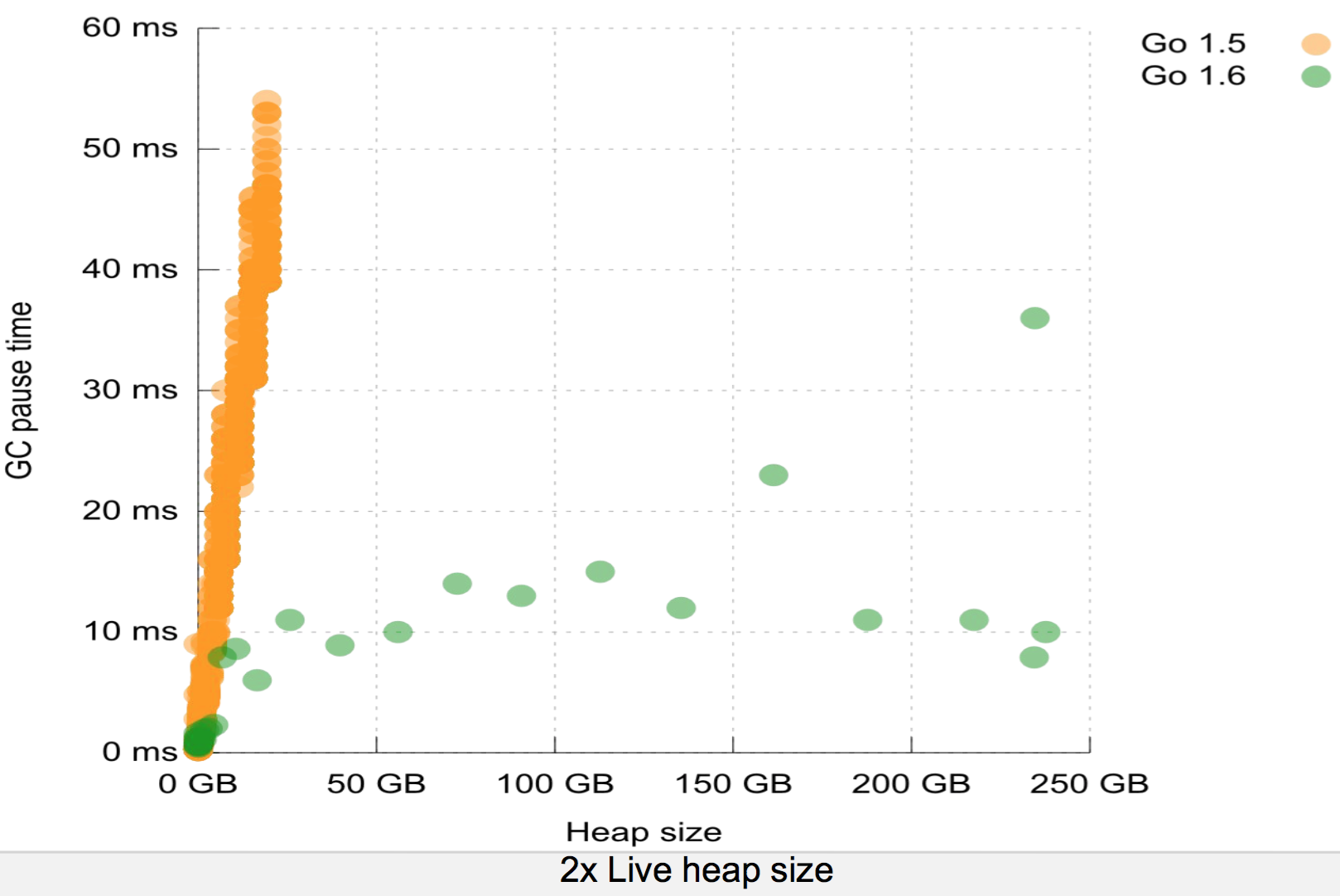{kind=link}
To get 10msec pause times with such huge heaps requires burning a LOT of CPU time with the standard JDK collectors because they can trade off pause latency vs CPU time.
This presentation shows tuning with 100msec as the target:
http://www.slideshare.net/HBaseCon/dev-session-7-49202969
Key points from the slides:
1. HBase setup with 100 GB heaps
2. Older collectors like CMS (still the default) sometimes take long pauses, like 5 seconds (not 5 minutes).
3. The new GC (G1) must be explicitly requested in Java 8. The plan is for it to be the default in Java 9, but switching to a new GC by default is not something to be taken lightly. G1 is, theoretically, configurably by simply setting a target pause time (lower == better latency but more CPU usage). Doing so eliminated all the long pauses, but a few collections were still 400msec (10x improvement over CMS).
4. With tuning, less than 1% of collections were over 300 msec and 60% of pauses were below the target of 100 msec.
Given that the Go collector, even the new one, isn't incremental or compacting I would be curious how effective it is with such large heaps. It seems to be that a GC that has to scan the whole 100GB every time, even if it does so in parallel, would experience staggeringly poor throughput.
Value types will certainly be a big, useful upgrade.