It requires statefulness and decisionmaking at the routing layer, and that's another thing that adds overhead and can go wrong at scale. (For example, there may be no one place with knowledge of all in-process requests. Traffic surges may lead to an arbitrary growth of state in the routing layer, rather than at the dynos.)
There are probably some simple techniques whereby dynos can themselves approximate the throughput of routing-to-idle, while Heroku's load-balancers continue to route randomly. For example, if a 'busy' dyno could shed a request, simply throwing it back to get another random assignment, most jam-ups could be alleviated until most dynos are busy. (And even then, the load could be spread more evenly, even in the case of some long requests and unlucky randomization.) Heroku may just need to coach their customers in that direction.
You are right. In the previous thread I pointed out one way of doing this with haproxy (there are many other tools that could do the job): "balance hdr(host)" on the first layer, and least connections balancing on the second layer. Or to know exactly which hosts are handled at the second layer (to minimize configuration size for each second layer server), create acl's for either specific hosts, or suitably short substrings, and your second layer servers can keep only the configuration for that subset.
You can also easily enough use "just" iptables at the second layer (supports weighted least connections and many others and you can plug in your own modules), which makes it very easy to do dynamic reconfiguration (to e.g. add/remove dynos), as well as traffic accounting (setting iptables to count bytes routed per rule is easy) and other fun stuff.
They could partition the routing, and maybe they do. But then (a) there's one extra hop mapping to the specialist routing group; and (b) it's still nice to have super-thin minimal-state routers, for example with just a list of up dynos updated once every few seconds, as opposed to live dyno load state updated thousands of times per second.
I too hope their full response givss more insight into their architecture... I have a couople of small projects at Herooku already and may use them. for several larger ones in the future.
I thought about mentioning this. Because 1 small hop is still less than random blowouts in response time.
You can even cheat by pushing the router IP into DNS. Hop eliminated.
> it's still nice to have super-thin minimal-state routers
I imagine Heroku's customers are not interested in what is nice for Heroku, they want Heroku to do the icky difficult stuff for them. That was the whole pitch.
Anyway, we're arguing about Star Wars vs Star Trek here because we have no earthly idea what they've tried.
Maybe, but they don't currently give each app its own IP, and might not want the complications of volatile IP reassignments, DNS TTLs, and so on. (Though, their current "CNAME-to-yourapp.herokuapp.com" recommendation would allow for this.)
...want Heroku to do the icky difficult stuff...
Yes, but to a point. Customers also want Heroku to provide a simple model that allows scaling as easy as twisting a knob to deploy more dynos, or move to a higher-resourced plan. Customers accept some limitations to fit that model.
Maybe Heroku has a good reason for thin, fast, stateless routing -- and that works well for most customers, perhaps with some app adjustments. Then, coaxing customers to fit that model, rather than rely on any sort of 'smart' routing that would be overkill for most, is the right path.
We'll know a lot more when they post their "in-depth technical review" Friday.
Because to be intelligent, you have to have the router talk to all the dynos to calculate load. Doing that in a performant way can get tricky, especially since people can hit a button and get 100 workers. The bigger the n, the more resources are required to track everything and the more things can go wrong.
It's not an intractable problem, but it's not trivial, affects only a small percentage of customers, and introduces complexity for everyone.
I feel pretty confident that there is a reasonable solution, and as someone that just spent the last 3 weeks building a custom buildpack and a new heroku app for an auto-scaling worker farm, I am happy to see such a quick, hopeful response.
I don't think this only affects a small percentage of customers. Maybe only a small percentage will notice.
This will affect any user with a high standard deviation in their application's response time.
Lets take an extreme case as an example: An application that has an average response time of 100ms, however 1% of the responses have a 3s response time.
They have relatively small load and they only have 2 web dynos running.
The admin thinks: We have this occasional slow response, but it should be fine. When one dyno is chewing on the 3s task, the other dyno will pick up the slack. Wrong.
With random routing, when one dyno is chewing on the slow task, 50% of the incoming requests are stacking up in that dyno's queue. The other dyno may be able to easily handle it's load, but half of your responses are still getting hit with 3s+ delays.
This is an extreme example, but this is not a rare issue. As the admin, unless you know about this issue, you will be perplexed by the seemingly random slow response times your users will be reporting. You won't see the problem in your logs, or your New Relic performance reports, but your customers will notice.
As others have pointed out, a major selling point of Heroku is it is supposed to "just work." These sorts of issues are supposed to be intelligently handled by their super-slick infrastructure. In my opinion, this is a serious issue. The fact that this has been biting users for 3 years now and Heroku is only willing to address the problem after they get major bad press is disheartening.
I have always been impressed by Heroku, especially how they constantly step up, admit their mistakes, and appear to be as transparent as possible about how they will fix their issues. This situation is seriously disappointing.
I am sure this is a very difficult problem to solve at their scale, but this is really what we as customers are paying them to solve.
Assuming you keep your prices roughly the same, the computation needed for assigning an available dyno becomes exponentially harder(costlier) as more dynos are added to the ecosystem. Thats why they changed the intelligent routing to random routing; to save cpu cycles.
The decision made by heroku was not an engineering decision, it was a business decision. While it is quite a bit frustrating, it is understandable and I don't think it will change. Since reverting a whole infrastructure to its original no-longer-profitable position is generally not a smart move.
A simple intelligent router may have 2^n performance, but I cannot imagine there are not other solutions that would bring performance closer to linear. I am not a queue theory expert, but I know they are out there. This is a well studied area of CS.
This is not only a problem for non-concurrent applications. It will become a problem as dyno usage increases for any application. The major factors will be the standard deviation of your response times and the number of responses you can handle per dyno. The issue just manifests first in applications that can only handle one request per dyno.
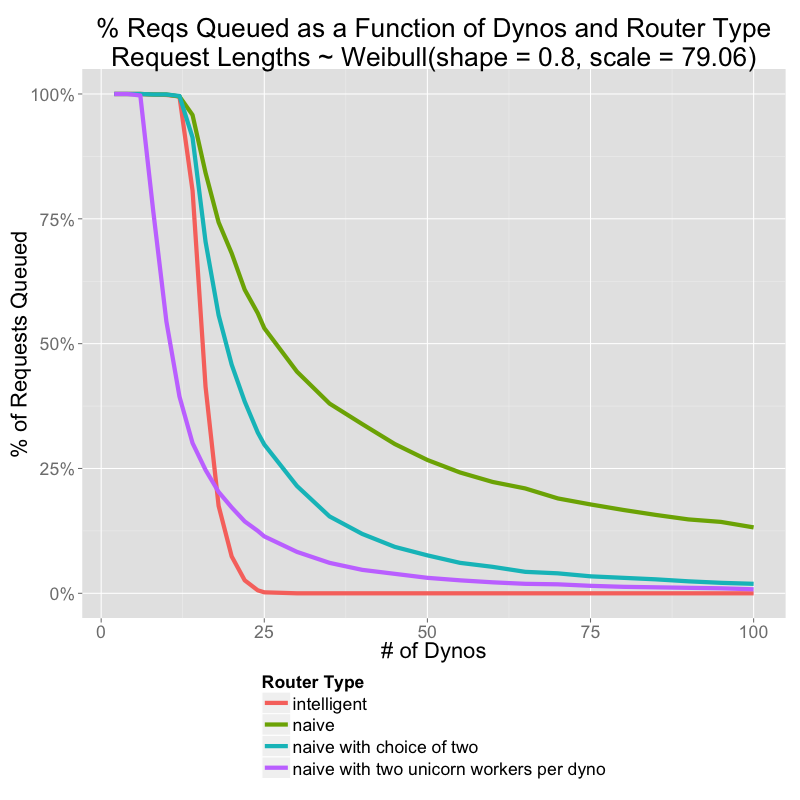
The purple line is a multi-threaded application.
No matter how concurrent your framework, it is still possible to overload the resources of a single dyno. When that happens, the router will continue to stack requests up in the queue.
What I see in that graph's purple line is that with the most basic concurrency you can have that is not nil, you get better times than some statistically optimal load-distributing solution (choice of two). I'd like to see similar graphs with 4, 8, or more workers to compare them.
{kind=link}
There are probably some simple techniques whereby dynos can themselves approximate the throughput of routing-to-idle, while Heroku's load-balancers continue to route randomly. For example, if a 'busy' dyno could shed a request, simply throwing it back to get another random assignment, most jam-ups could be alleviated until most dynos are busy. (And even then, the load could be spread more evenly, even in the case of some long requests and unlucky randomization.) Heroku may just need to coach their customers in that direction.