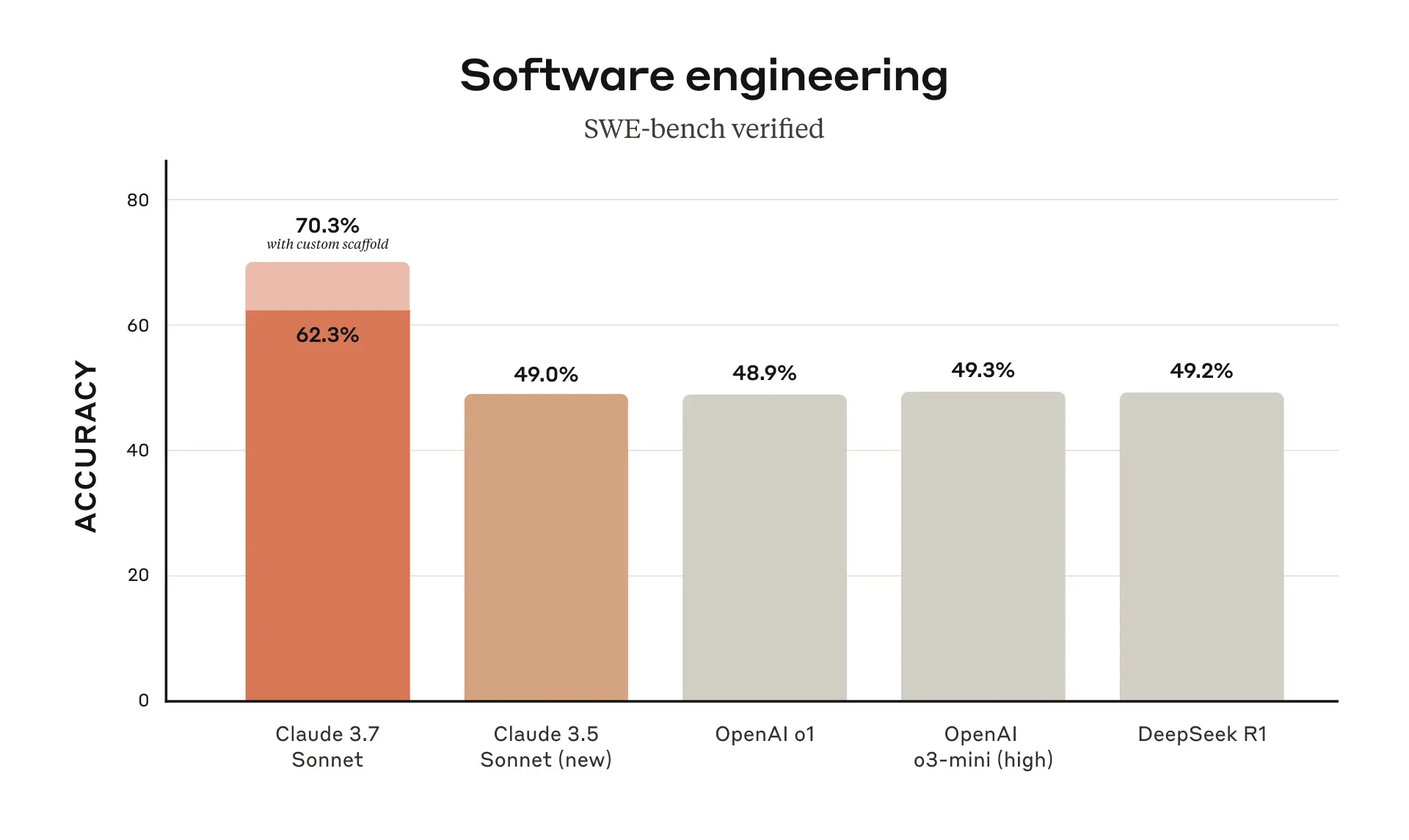
| Very impressive! But under arguably the most important benchmark -- SWE-bench verified for real-world coding tasks -- Claude 3.7 still remains the champion.[1] Incredible how resilient Claude models have been for best-in-coding class. [1] But by only about 1%, and inclusive of Claude's "custom scaffold" augmentation (which in practice I assume almost no one uses?). The new OpenAI models might still be effectively best in class now (or likely beating Claude with similar augmentation?). |
{kind=link}
Sonnet is still an incredibly impressive model as it held the crown for 6 months, which may as well be a decade with the current pace of LLM improvement.