The main benefit of reproducible builds isn't security, but sanity. There is just no reason why your build process should produce different output for the same input. That just means it's broken in subtle ways and information is leaking into it that was never intended to be there.
The real benefit of reproducible builds however isn't for the individual software itself, but for the software landscape as a whole. As with reproducible builds you have the whole dependency chain specified completely from top to bottom, no more hidden dependencies. And everything is fully automated, not just on your personal machine, but in a way that others can reproduce. That in turn will dramatically improve the ease with which users can build software (and change it), as it turns an hour long hunt for dependencies into a single click.
To really see the fruits of this labor will still take some years, but it has the potential to pretty drastically reshape and improve the way FOSS software works (e.g. Nix Flakes) and actually allow users to make use of their freedom instead of giving up before they have even managed to build the software.
This blogpost can be summarized as with an XKCD essentially.
It positions itself with the following assertions:
> Q. If a user has chosen to trust a platform where all binaries must be codesigned by the vendor, but doesn’t trust the vendor, then reproducible builds allow them to verify the vendor isn’t malicious.
> I think this is a fantasy threat model. If the user does discover the vendor was malicious, what are they supposed to do? The malicious vendor can simply refuse to provide them with signed security updates instead, so this threat model doesn’t work.
Which only works in the context of proprietary vendors and not in the context of FOSS distributions. Nothing can be denied as everything is freely distributed. You want to have the ability to verify the work done by packagers and build servers.
Next up is the essentially the claim that "reproducible builds can't solve bugdoors. Thus it's insufficient to solve any problems".
Reproducible Builds is a nice property of any build system for multiple reasons. It's also part of the supply-chain security story and not the entire story alone. As for how much effort it is? It's a lot. But considering the core community of reproducible builds people is below 50 people, and we are still able to come close to an 88% reproducible builds in real world distributions should point out how achievable this goal is.
> Which only works in the context of proprietary vendors and not in the context of FOSS distributions. Nothing can be denied as everything is freely distributed. You want to have the ability to verify the work done by packagers and build servers.
Indeed. Open source isn't a vendor it's just volunteers from the Internet. If you look at the way people behave in nearly every other walk of life that isn't software, it would seem amazing that we somehow managed to create such a beautiful thriving gift economy. In order to keep it that way, we need to have reproducible builds, because they promote transparency.
It is however very very expensive. Even if you manage to surgically remove all the dependencies on things like __TIME__ then you still need to audit the code for things like iterating over hash tables. Many core libraries these days such as expat xml parsing will seed their data structures using /dev/random. You can qsort but you might get snagged by the fact that it doesn't use stable algorithms. If things don't work out then it helps to have deterministic execution too so you can run the build and see what it does differently that causes it to produce different output. Sadly, with things like kernel imposed memory randomization that's easier said than done.
So the unfortunate reality is that open source isn't arching towards determinism. The trend is very much the opposite where it's becoming more non-deterministic, especially in the last five years. So if having deterministic builds is something your org cares about then you really need to hire an expert and in many cases change the engineering culture too.
This is taken from the integration suite which Debian have been running for years. This represents checking out the code, and building twice. This is not distributed packages from Debian. This inflates the number a little bit.
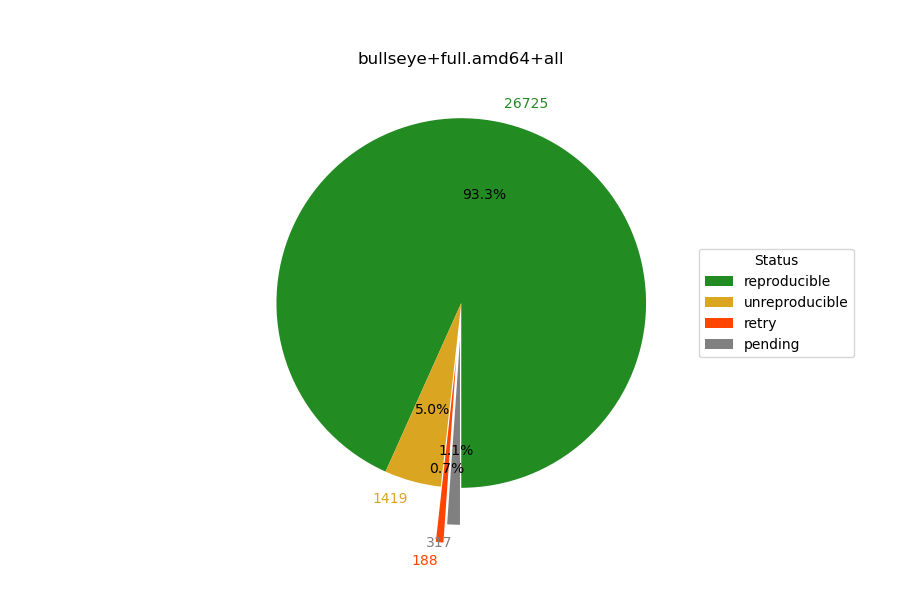
Why are 28.8% of Debian stable packages currently "pending"?
The stats on reproducible-builds.org say that "29595 packages (95.7%) successfully built reproducibly in bullseye/amd64."[0] which may not be accurate for the reasons given in the grandparent post, but I note that the situation seems to have improved significantly[1] since that mailing list thread.
>Why are 28.8% of Debian stable packages currently "pending"?
They are separate systems. The CI/CD and the rebuilder are not doing the same job essentially.
The 28.8% on pending might be because of slow rebuild times as the integration system has had more time building packages with significantly more CPU power behind it.
{kind=link}
The real benefit of reproducible builds however isn't for the individual software itself, but for the software landscape as a whole. As with reproducible builds you have the whole dependency chain specified completely from top to bottom, no more hidden dependencies. And everything is fully automated, not just on your personal machine, but in a way that others can reproduce. That in turn will dramatically improve the ease with which users can build software (and change it), as it turns an hour long hunt for dependencies into a single click.
To really see the fruits of this labor will still take some years, but it has the potential to pretty drastically reshape and improve the way FOSS software works (e.g. Nix Flakes) and actually allow users to make use of their freedom instead of giving up before they have even managed to build the software.