|
A lot of apps (old-timey Windows apps, for example) have this philosophy, leading them to reinvent things like crypto and image decoding. Naturally, this leads to tons of bugs, including security bugs. I would revise this to: Don't bring in more code than you need. But if the choice is between writing something yourself and using someone else's well-tested, heavily-used library, always go for the latter. |
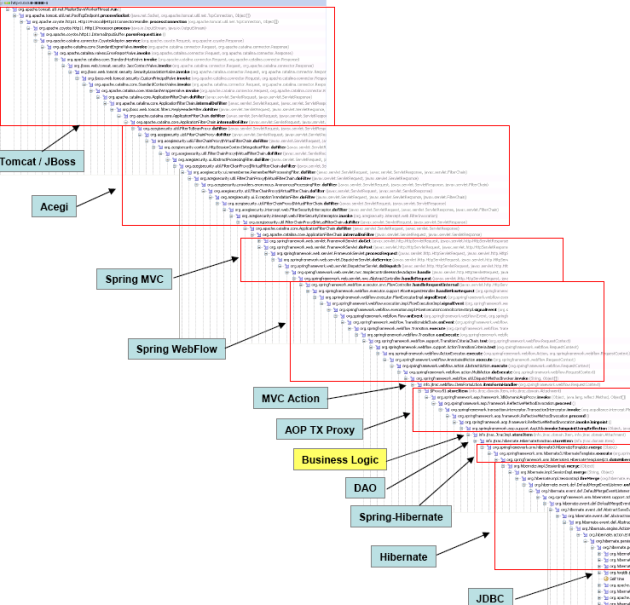{kind=link}