|
|
|
|
|
|
by binux
4236 days ago
|
|
|
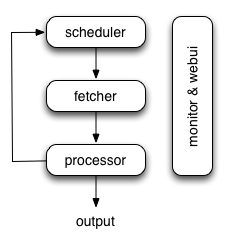
the architecture of pyspider: http://blog.binux.me/assets/image/pyspider-arch.png And yes for centralized queue which is in scheduler. It's designed to satisfy about 10-100 million urls for each project. scheduler, fetchers, processors are connected with rabbitmq(alternatively). Only one scheduler is allowed. But you can run multiple fetchers or processors as needed. |
|
|
{kind=link}