|
|
|
|
|
|
by valarauca1
4315 days ago
|
|
|
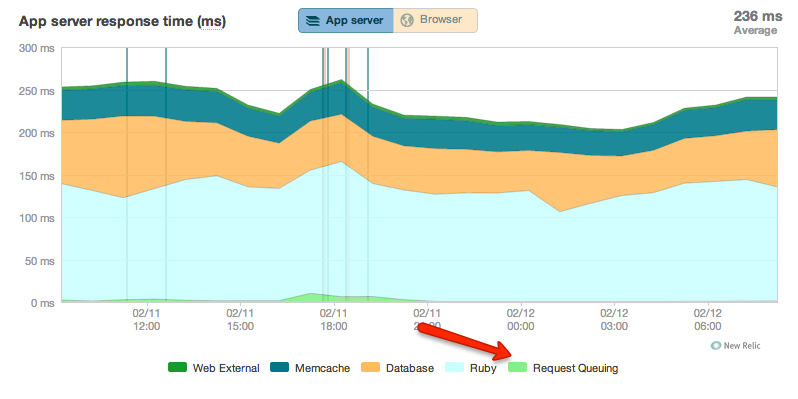
How complex? In one second a modern processor can do ~1 billion operations (ish, some are faster, some are slower, sometimes multiple are done in the same clock tick). Even if its slow, core2 architecture. This means they have the time for about ~200 million instructions per request (Ignoring internal disk I/O, or network I/O). That amount of work is insane! :.:.: I want to say their doing something fundamentally wrong. And it has nothing to do with their language. |
|
|
{kind=link}
The slowness of their system can probably be blamed on slow database access, or some kind of initialization cost they're paying for every request (i.e.: calling into a binary like in the old CGI days, initializing the Python VM every time).