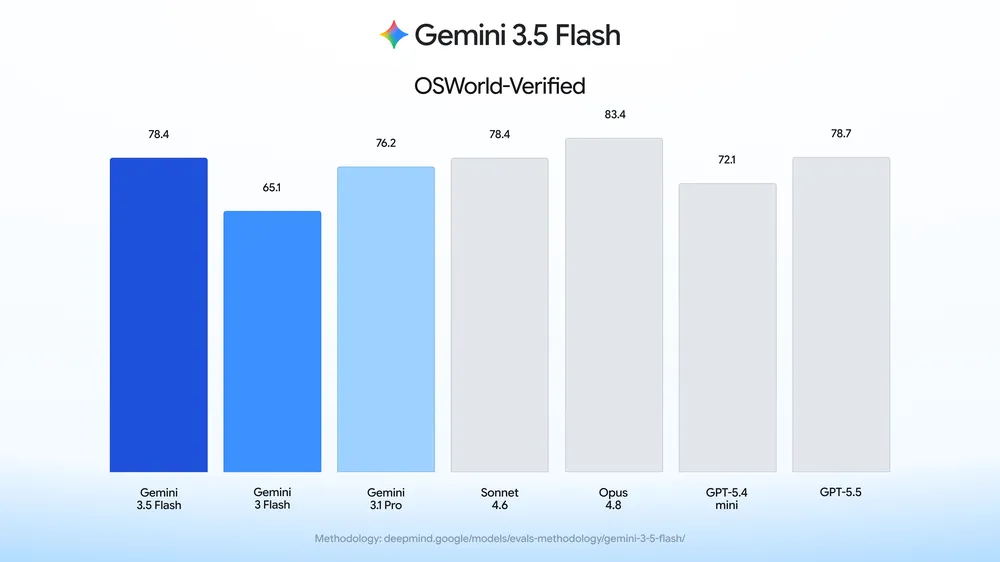
The graph has Gemini 3.5 Flash matching Sonnet 4.6, losing to Opus 4.8, and slightly behind GPT-5.5 by 0.3 points... That's not that much of a hands-down loss for Gemini for this specific workload benchmark.
Methodology: All Gemini scores are pass @1 except where otherwise noted. "Single attempt" settings allow no
majority voting or parallel test-time compute. All of the results are all run with the Gemini API for the model-id
gemini-3.5-flash with default sampling settings unless indicated otherwise below. To reduce variance, we
average over multiple trials for smaller benchmarks.
All the results for non-Gemini models are sourced from providers' self reported numbers unless otherwise mentioned below. For Claude Opus 4.7 , Sonnet 4.6, and GPT-5.5 we default to reporting maximum
thinking/reasoning settings available, but when reported results are not available we use best available reasoning
results.
It's honest - people who know what they are looking at will take speed and token costs into account. I don't use Gemini 3.5 for coding, but I use it as something in between a search engine and agent.
It's amazing how designers of charts trying to show their product is close to the leader always remember to start the axis at zero, and designers of charts trying to show how big their lead is always forget that
{kind=link}
The methodology used:
https://deepmind.google/models/evals-methodology/gemini-3-5-...
Methodology: All Gemini scores are pass @1 except where otherwise noted. "Single attempt" settings allow no majority voting or parallel test-time compute. All of the results are all run with the Gemini API for the model-id gemini-3.5-flash with default sampling settings unless indicated otherwise below. To reduce variance, we average over multiple trials for smaller benchmarks.
All the results for non-Gemini models are sourced from providers' self reported numbers unless otherwise mentioned below. For Claude Opus 4.7 , Sonnet 4.6, and GPT-5.5 we default to reporting maximum thinking/reasoning settings available, but when reported results are not available we use best available reasoning results.