|
|
|
|
|
|
by plaidfuji
22 days ago
|
|
|
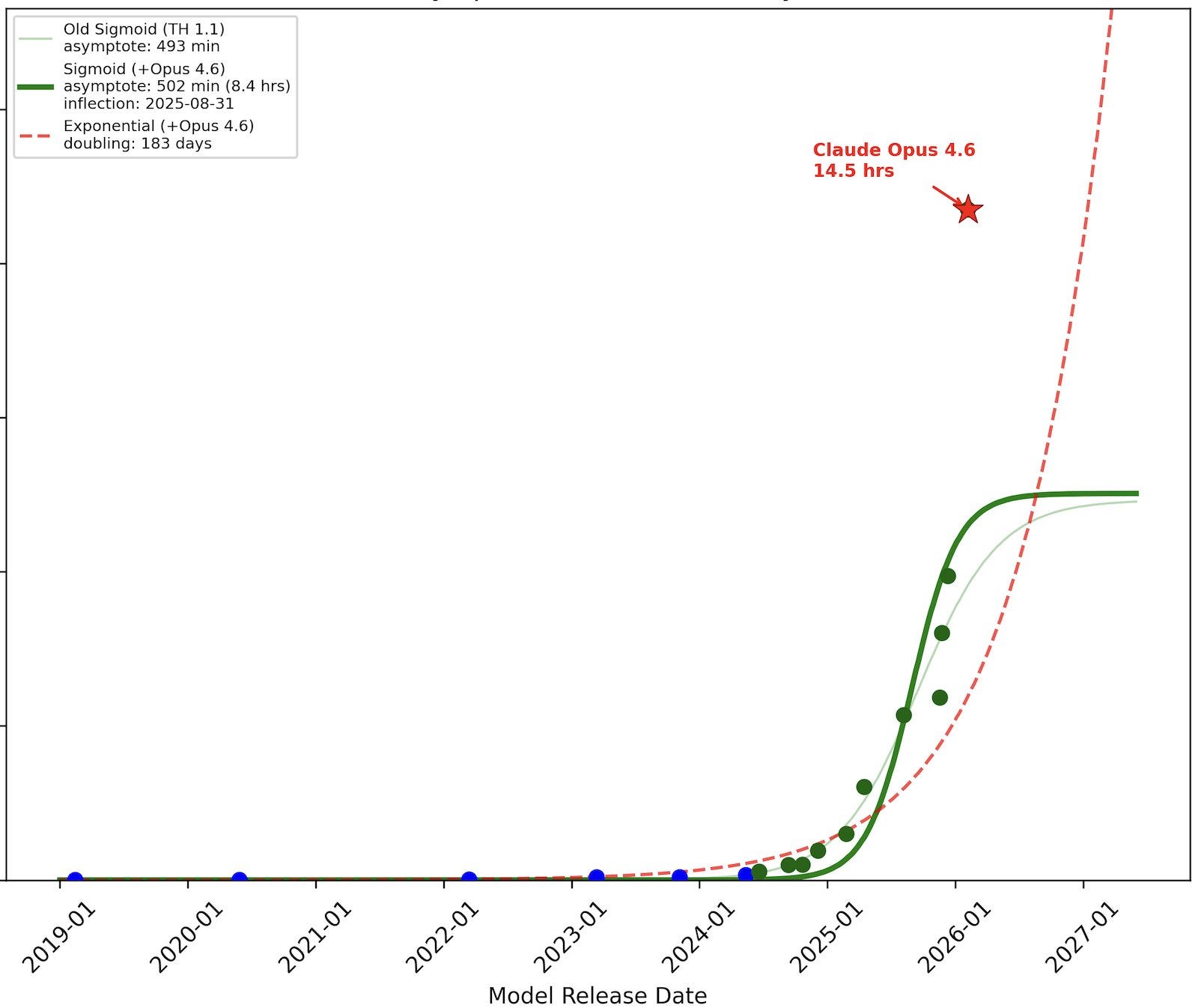
There may be additional major leaps forward, and there may not. I kind of struggle to imagine what the next step actually is. Certainly there will be improvements in performance (speed) and cost. But at a point you reach a barrier where the limiting factor is the specificity of the human prompt and our ability to manage all the code we’re generating. Somewhat oversimplifying; writing software and building apps was a bottleneck - now it is not. What is the next bottleneck that LLMs can solve? Is there one? And is there enough publicly available data to solve it repeatably at scale? Or did we just automate stack overflow searches and now we’re stuck again? Or is the endgame of this innovation cycle the complete removal of interaction with machines through code? Will we simply interact with machine coworkers purely through natural language? Can an LLM make PowerPoint slides and run a meeting? So far not seeing much progress on that. |
|
|
{kind=link}