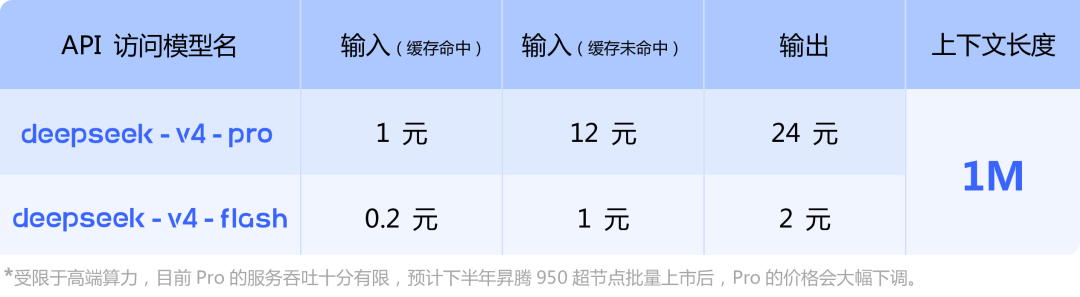
| > Also, note that there's zero CUDA dependency. It runs entirely on Huawei chips. That is a huge claim to make with no evidence. I researched what you said, and I have found no statement to that effect in their paper[0], on huggingface[1], twitter[2], WeChat[3], or in their news release[4]. They only mention as a footnote in only the Chinese version of their news release that they plan to reduce inference costs with the Ascend 950 supernode when it releases[5]. The only mention of Huawei in their paper is that they validated a technique to lower interconnect bandwidth on Ascend NPUs and Nvidia GPUs[6]. [0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main... [1] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro [2] https://xcancel.com/deepseek_ai/status/2047516922263285776 [3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg [4] https://api-docs.deepseek.com/news/news260424 [5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png [6] Page 16 |
{kind=link}
And while I'm here I want to note that I feel there's a big misunderstanding of what is and isn't demonstrated by DeepSeek. So far as I can tell the major (and important!) innovation is reproducing near-frontier level capabilities at a fraction of the cost, but it may be the case that iterating forward at the frontier is the costly thing and is a cost borne by Western companies and that nuance seems to get lost with DeepSeek. Which is not to say that as a matter of principle that non Western companies aren't sometimes capable of jumping into the lead (Kimi has been super impressive) but if GPT/Claude/etc "only" lead at the frontier with more expensive models, that's still a moat.