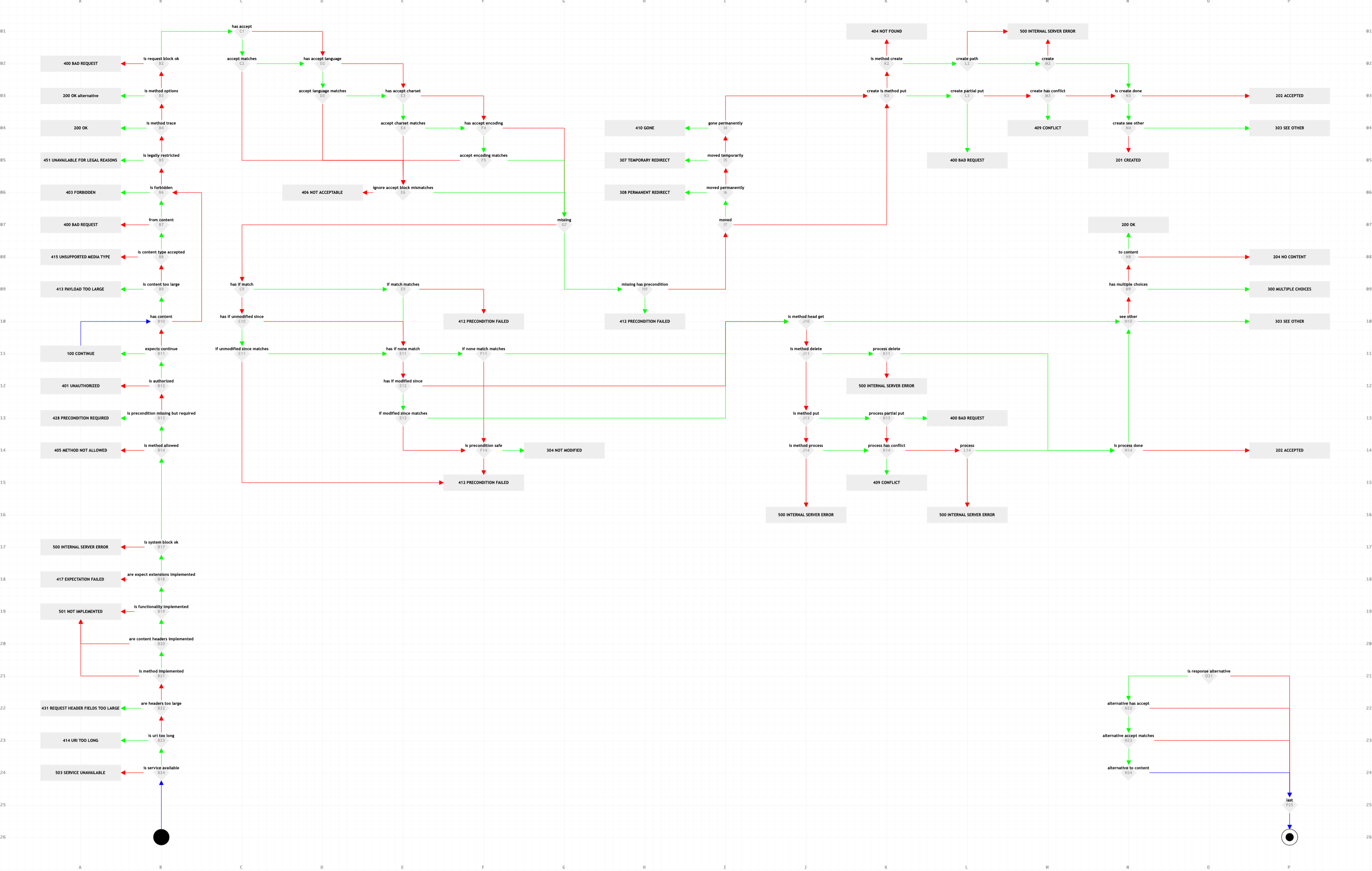
| > I sympathize with the pedantry here and found Fielding's paper to be interesting, but this is a lost battle. Why do people feel compelled to even consider it to be a battle? As I see it, the REST concept is useful, but the HATEOAS detail ends up having no practical value and creates more problems than the ones it solves. This is in line with the Richardson maturity model[1], where the apex of REST includes all the HATEOAS bells and whistles. Should REST without HATEOAS classify as REST? Why not? I mean, what is the strong argument to differentiate an architectural style that meets all but one requirement? And is there a point to this nitpicking if HATEOAS is practically irrelevant and the bulk of RESTful APIs do not implement it? What's the value in this nitpicking? Is there any value to cite thesis as if they where Monty Python skits? [1] https://en.wikipedia.org/wiki/Richardson_Maturity_Model |
{kind=link}