|
|
|
|
|
|
by sorenjan
382 days ago
|
|
|
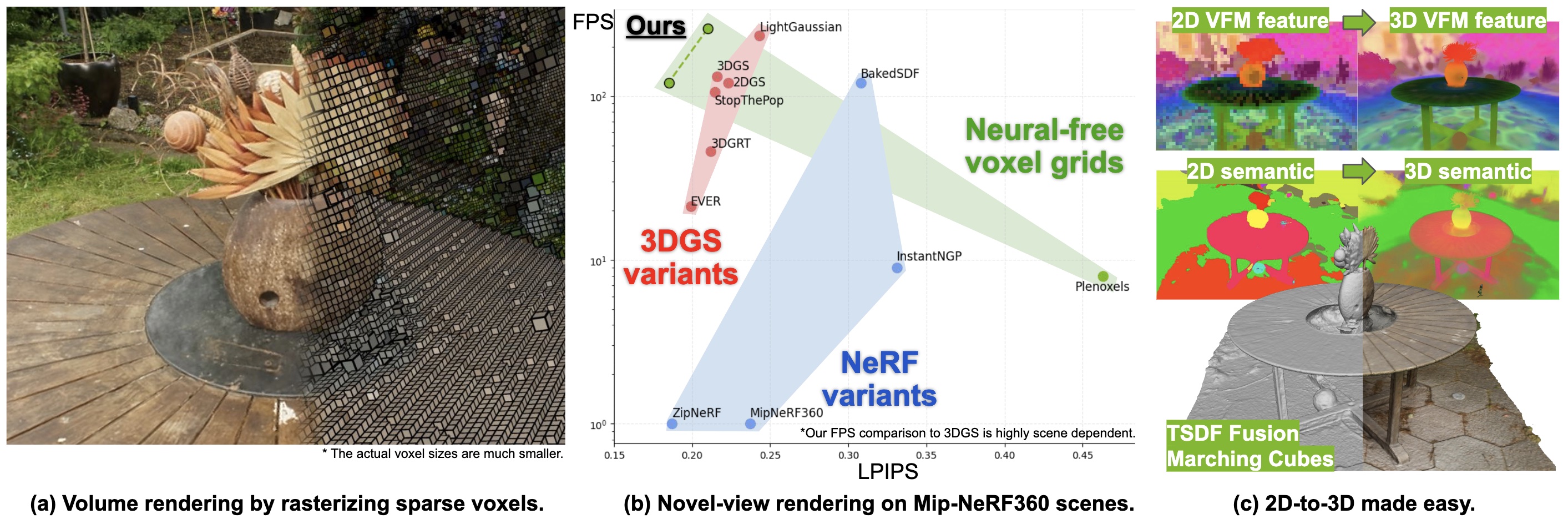
This looks really nice, but I cant help to think this is a stop gap solution like other splatting techniques. It's certainly better than NERFs, where the whole scene is contained in a black box, but reality is not made up of a triangle soup or gaussian blobs. Most of the real world is made up of volumes, but can often be thought of as surfaces. It makes sense to represent the ground, a table, walls, etc with planes, not a cloud of semi translucent triangles. This is like pouring LEGO on the floor and moving them around until you get something that looks ok from a distance, instead of putting them together. Obviously looking good is often all that's needed, but it doesn't feel very elegant. Although, the normals look pretty good in their example images, maybe you can get good geometry from this using some post processing? But then is a triangle soup really the best way of doing that? My impression is that this is chosen specifically to get a final representation that is efficient to render on GPUs. I haven't done any graphics programming in years, but I thought you'd want to keep the number of draw calls down, do you need to cluster these triangles into fewer draw calls? Is there any work being done to optimize a volumetric representation of scenes and from that create a set of surfaces with realistic looking shaders or similar? I know one of the big benefits of these splatting techniques is that it captures reflections, opacity, anisotropicity, etc, so "old school" photogrammetry with marching cubes and textured meshes have a hard time competing with the visual quality. |
|
|
{kind=link}
GPUs draw can draw 10,000's of vertices per draw call, whether they are connected together into logical objects or are "triangle soup" like this. There is some benefit to having triangles connected together so they can "share" a vertex, but not as much as you might think. Since GPUs are massively parallel, it does not matter much where on the screen or where in the buffer your data is.
> Is there any work being done to optimize a volumetric representation of scenes and from that create a set of surfaces with realistic looking shaders or similar?
This is basically where the field was going until nerfs and splats. But then nerfs and splats were such HUGE steps in fidelity, it inspired a ton of new research towards it, and I think rightfully so! Truth is that reality is really messy, so trying to reconstruct logically separated meshes for everything you see is a very hard way to try to recreate reality. Nerfs and splats recreate reality much easier.