|
|
|
|
|
|
by slama
544 days ago
|
|
|
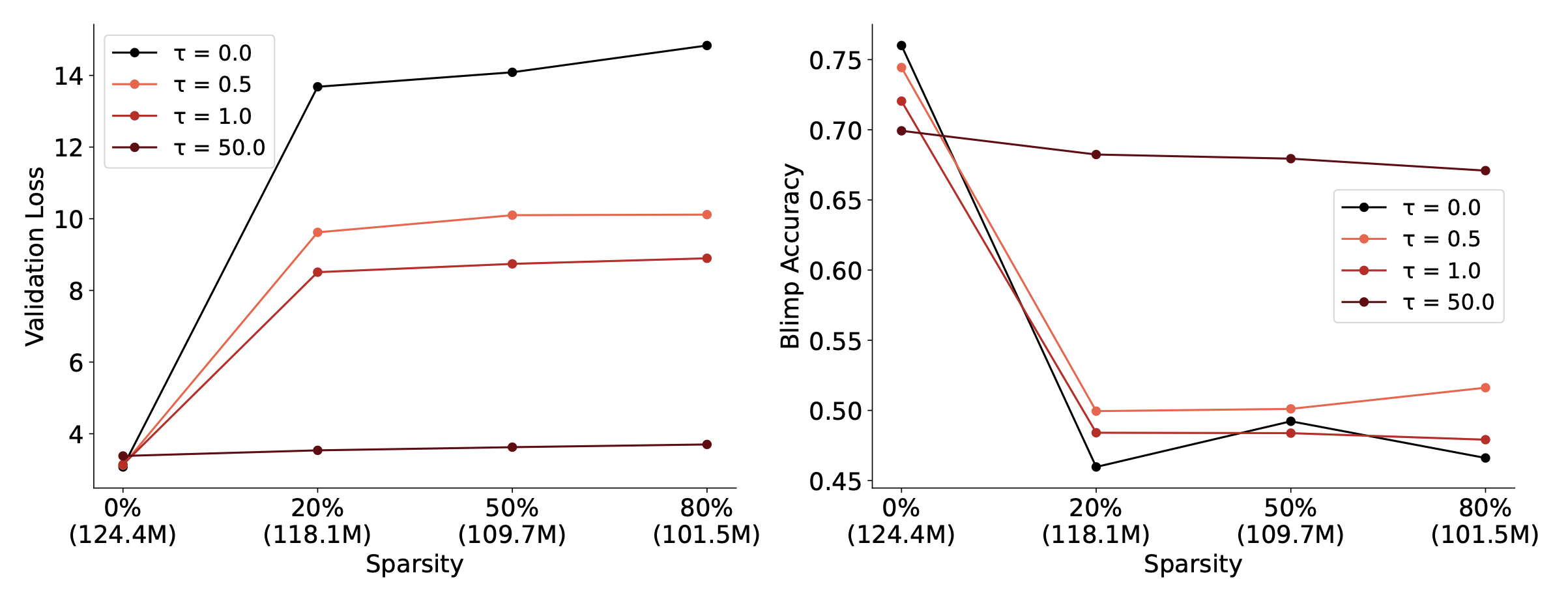
The title here doesn't seem to match. The paper is called "TopoNets: High Performing Vision and Language Models with Brain-Like Topography" Even with their new method, models with topography seem to perform worse than models without. |
|
|
{kind=link}
Since the submitter appears to be one of the authors, maybe they can explain the connection between the two titles? (Or maybe they already have! I haven't read the entire thread)