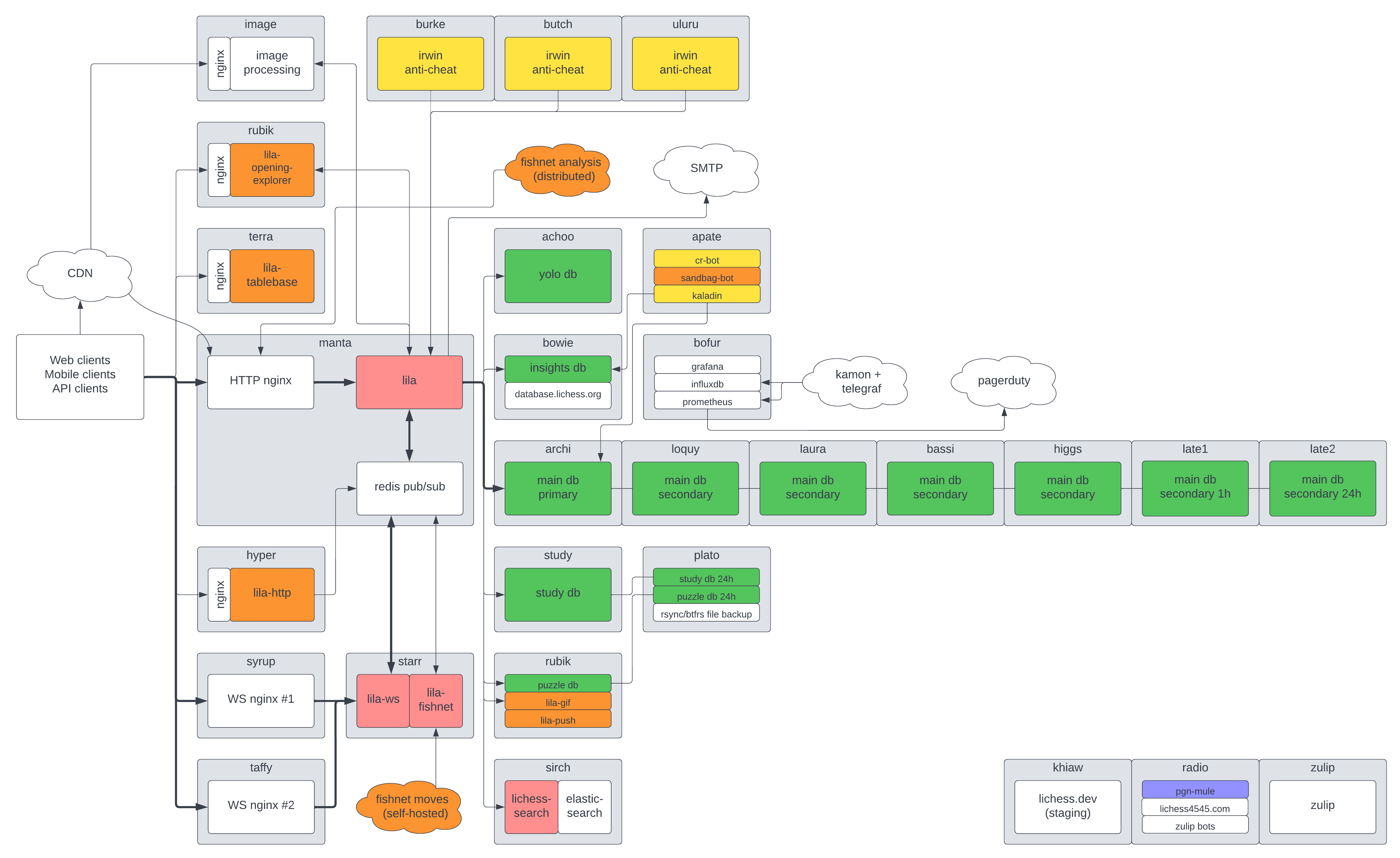
| So essentially lichess chose StackOverflow approach - (rather) beefy servers, instead of "treating them like a cattle". Interesting that they accumulate and periodically store game state. Unfortunately it is not very clear, where they store ongoing game state - in redis or on server itself. Also cost breakdown doesn't have server for redis, only for DB. BTW, their github has better architectural picture, than overly simplified one in the article: https://raw.githubusercontent.com/lichess-org/lila/master/pu.... Unfortunately, I'm afraid, drawing something like that during interview may not land a job at faang =( Note that they have cost per game fairly low: $0.00027, 3,671 games per dollar. Their cost breakdown, for ones who are curious
https://docs.google.com/spreadsheets/d/1Si3PMUJGR9KrpE5lngSk... p.s. I'm not saying that Lichess's approach is the best or faang is the worst. Remember, lichess had 10 hours outage exactly because of the architecture chosen (single datacenter dependency). https://lichess.org/@/Lichess/blog/post-mortem-of-our-longes... . And outages like that are exactly the reasons why multi-datacenter and multi-region architectures are drilled down into faang engineers. My point is is that there are cases when this approach is legit, but typical interview is laser focused on different things, and most probably won't appreciate the "old style" approach to the problem. I'm sure that if Thibault will ever decide to land in faang he will neither do whiteboard coding nor system design. |
{kind=link}