|
|
|
|
|
|
by hk1337
639 days ago
|
|
|
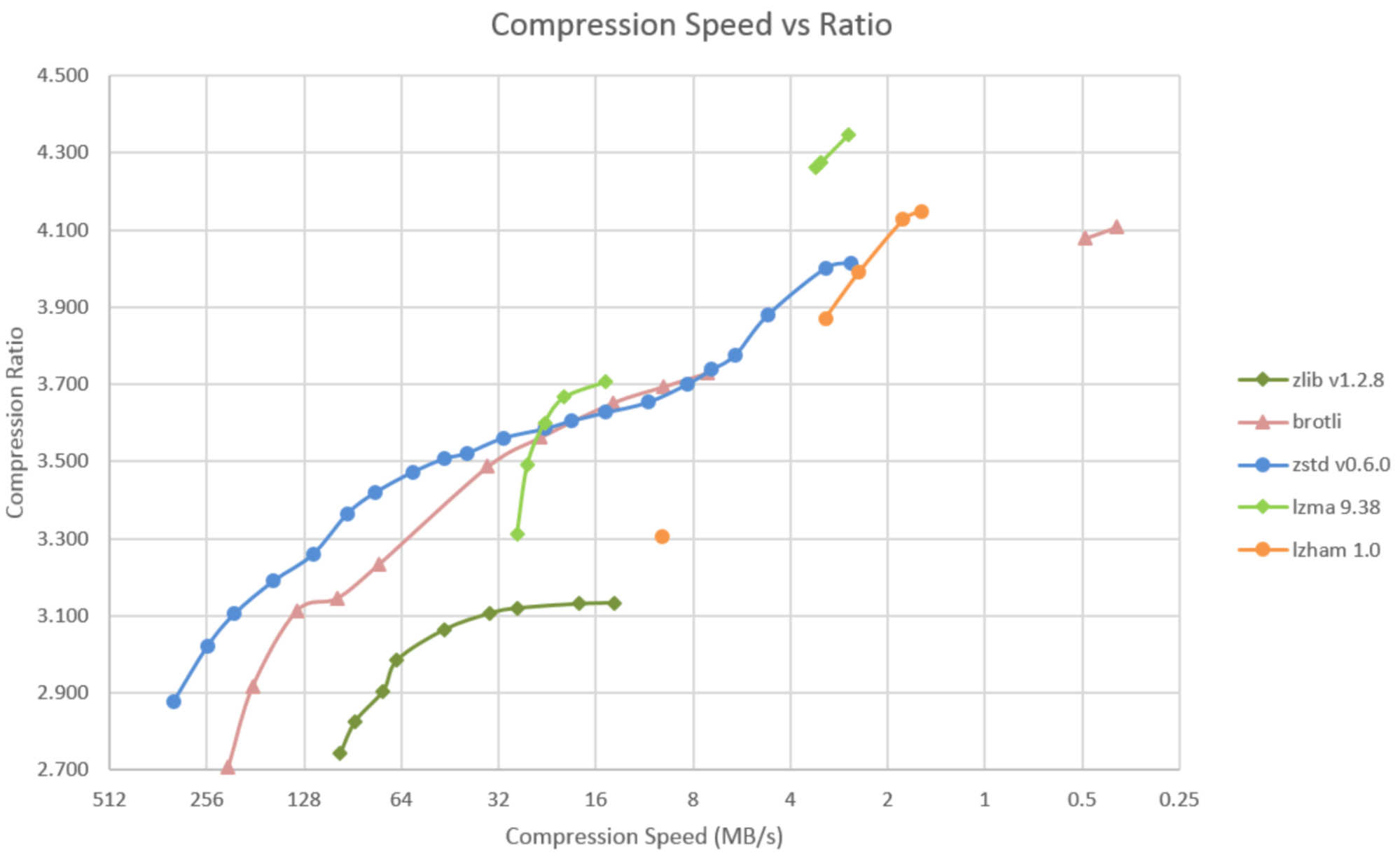
Why do people use gzip more often than bzip? There must be some benefit but I don’t really see it, you can split and join two bzipped files (presumably CSV so you can see the extra rows). Bzip seems to compress better than gzip too. |
|
|
{kind=link}
What it comes down to is, if you care about compression time, gzip is the winner; if you care about compression ratio, then go with xz; if you care about tuning compression time/compression ratio, go with zstd. bzip2 just isn't compelling in either metric anymore.