|
|
|
|
|
|
by bobbywilson0
719 days ago
|
|
|
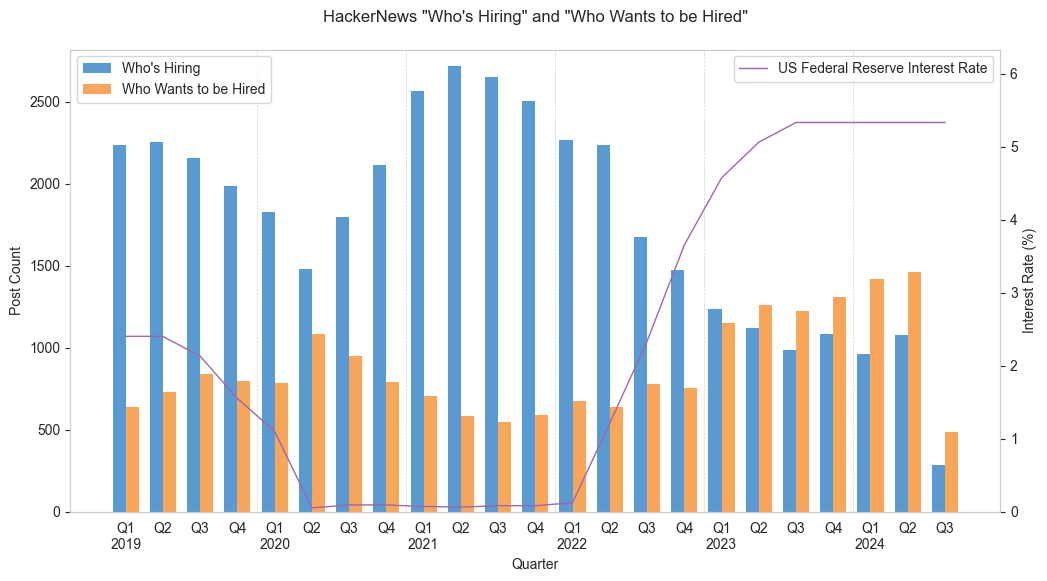
Cool analysis with GPT-4o! I was doing some messing around with the same dataset recently around the "Who is Hiring" and "Who wants to be hired". Although I was just using pandas and spacy. (I was job supply and demand with the US FED interest rates here: https://raw.githubusercontent.com/bobbywilson0/hn-whos-hirin...) I can actually see how nice it would be for an llm to be able to disambiguate 'go' and 'rust'. However, it does seem a bit disappointing that it isn't consolidating node.js and nodejs or react-native and react native. I'm curious on the need to do use selenium script to google to iterate, here's my script: https://gist.github.com/bobbywilson0/49e4728e539c726e921c79f.... Just uses the api directly and a regex for matching the title. Thanks for sharing! |
|
|
{kind=link}
What the author could have done, and what I should have (but didn't) also, is add a bunch of possible values (enums) for each possible field value. This should solve it from coming up with variations e.g. node, nodejs
In zod/tooling it would look like this; remote: z.enum(['none', 'hybrid', 'full']), framework: z.enum(['nodejs', 'rails']),
But this just shifts the problem further down, which is now you need a good standard set of possible values. Which I am yet to find, but I'm sure it is out there.
On top of that, I am working on publishing a JobDescription.schema.json such that the next time the models train, they will internalize an already predefined schema which should make it a lot easier to get consistent values from job descriptions.
- Also I tend to forget to do it a lot recently in LLM days but there are plenty of good NER (Named Entity Recognition) tools out there these days, that you should run first before making robust prompts