|
|
|
|
|
|
by authorfly
806 days ago
|
|
|
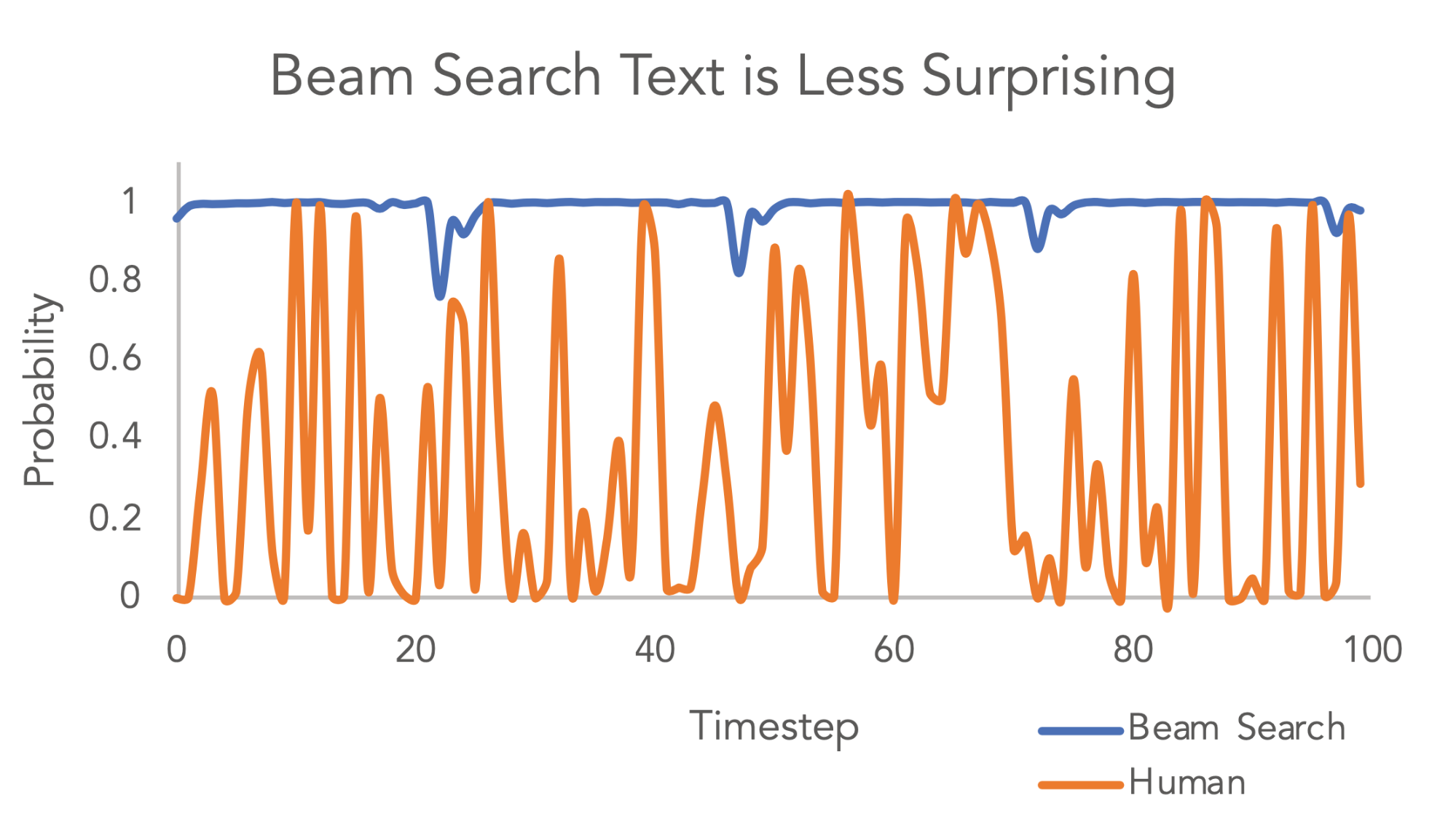
In practice, beam search doesn't seem to work well for generative models. Temperature and top_k (two very similar parameters) were both introduced to account for the fact that human text is unpredictable stochastically for each sentence someone might say as such - as shown in this 2021 similar graph/reproduction of an older graph from the 2018/2019 HF documentation: https://lilianweng.github.io/posts/2021-01-02-controllable-t... It could be that beam search with much longer length does turn out to be better or some merging of the techniques works well, but I don't think so. The query-key-value part of transformers is focused on a single total in many ways - in relation to the overall context. The architecture is not meant for longer forms as such - there is no default "two token" system. And with 50k-100k tokens in most GPT models, you would be looking at 50k*50k = A great deal more parameters and then issues with sparsity of data. Just everything about GPT models (e.g. learned positional encodings/embeddings depending on the model iteration) is so focused on bringing the richness of a single token or single token index that the architecture is not designed for beam search like this one could say. Without considering the training complications. |
|
|
{kind=link}