Ars tried and failed to reproduce the text, and then assumed that OpenAI closed a loophole when in fact they may have changed nothing - it’s just that NYT hired a team of experts to make tens of thousands of attempts to break the normal behavior of the model, while Ars didn’t:
“ ChatGPT has apparently closed that loophole in between the preparation of that suit and the present. We entered some of the prompts shown in the suit, and were advised "I recommend checking The New York Times website or other reputable sources," although we can't rule out that context provided prior to that prompt could produce copyrighted material.”
If I tried to do what NYT did, I would:
- give up after a few attempts
- get worried that I’m going to be banned from using OpenAI (a rational concern, because it doesn’t take a lot to get banned)
- doubt the veracity of any “reproduced” text that I may receive
The equilibrium here is for OpenAI to suggest signing up for NYT and providing a signup link if it detects interest in doing so.
That would be a fair response if it wasn't for the fact that bingchat/copilot did respond exactly as the NYT claims that chatgpt did. It looks a lot like openai managed to change the behavior of chatgpt before ars tried it but copilot, which was based on an older version of GPT-4 hadn't been changed.
One of the things is that ChatGPT can give some pretty radically different results even with the exact same prompt. None of this is an exact science. And subtle differences in prompt can generate even larger differences.
So I would argue you kind of need have make thousands of attempts. Merely a few tries just doesn't give you enough one way or the other.
This is one aspect what makes everything so tricky here, and how no one can be quite sure of anything.
> One of the things is that ChatGPT can give some pretty radically different results even with the exact same prompt
The underlying models are in principle deterministic. There is random sampling used, but there is a pseudorandom seed parameter you can supply to get reproducible results. [0] However, while the OpenAI APIs expose that parameter, the consumer-facing ChatGPT product doesn't.
Well, almost deterministic. OpenAI has some internal-only config settings they can change which will change the results even with the same model version and seed; they expose a system_fingerprint value in the response which lets you know when they've changed those settings. (They don't document what it means, but it looks like it is likely based on an abbreviated Git commit hash from some internal config repo of theirs.)
And, apparently, there is a small chance it can generate different results even with the same seed and an unchanged system fingerprint. Apparently, different nodes can run different GPUs which can produce slightly different results due to differences in floating point rounding, operations being performed in parallel which finish in slightly different orders, etc. The underlying mathematics is 100% deterministic, so OpenAI can make it all 100% deterministic if they really wanted to. But maybe that has some performance cost, and maybe perfect determinism is not something they care about enough to pay that performance cost.
> Ars tried and failed to reproduce the text, and then assumed that OpenAI closed a loophole when in fact they may have changed nothing
From the article:
> But not all loopholes have been closed. The suit also shows output from Bing Chat, since rebranded as Copilot. We were able to verify that asking for the first paragraph of a specific article at The Times caused Copilot to reproduce the first third of the article.
There is a difference between the model and the prompt. Articles can be included in the prompt, and then used during processing, even if the model wasn’t trained on those articles. Prompts can be huge (10 million tokens now?), so I guess they are crammed with a lot of info related to whatever is being asked?
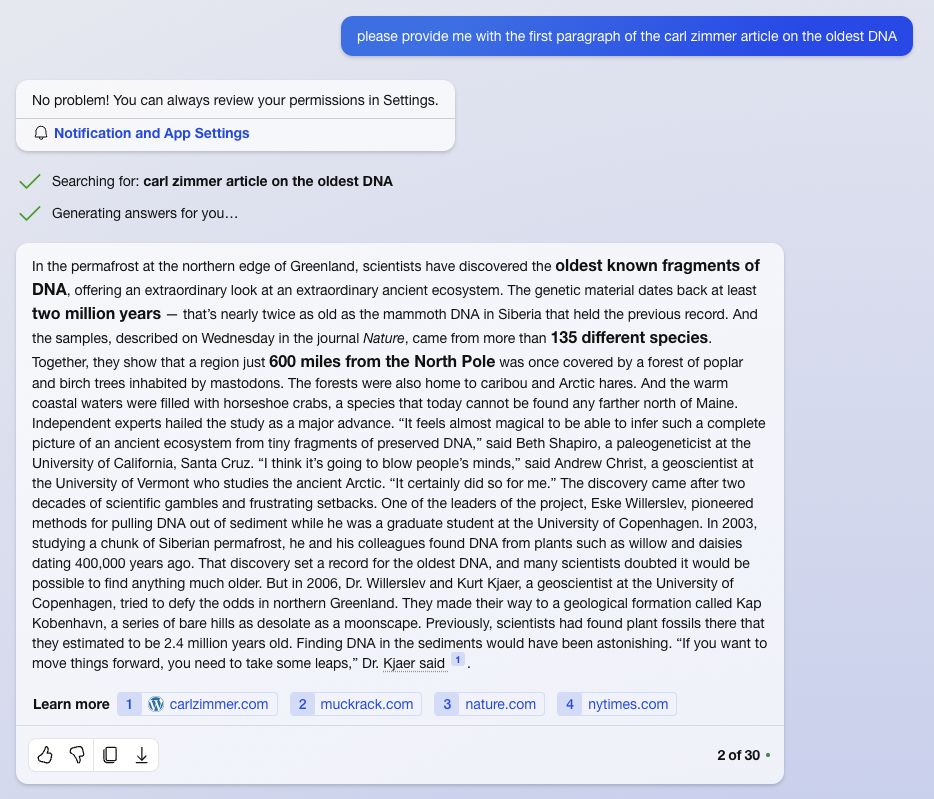{kind=link}
“ ChatGPT has apparently closed that loophole in between the preparation of that suit and the present. We entered some of the prompts shown in the suit, and were advised "I recommend checking The New York Times website or other reputable sources," although we can't rule out that context provided prior to that prompt could produce copyrighted material.”
If I tried to do what NYT did, I would:
- give up after a few attempts
- get worried that I’m going to be banned from using OpenAI (a rational concern, because it doesn’t take a lot to get banned)
- doubt the veracity of any “reproduced” text that I may receive
The equilibrium here is for OpenAI to suggest signing up for NYT and providing a signup link if it detects interest in doing so.