That is an excellent explanation full of great intuition building!
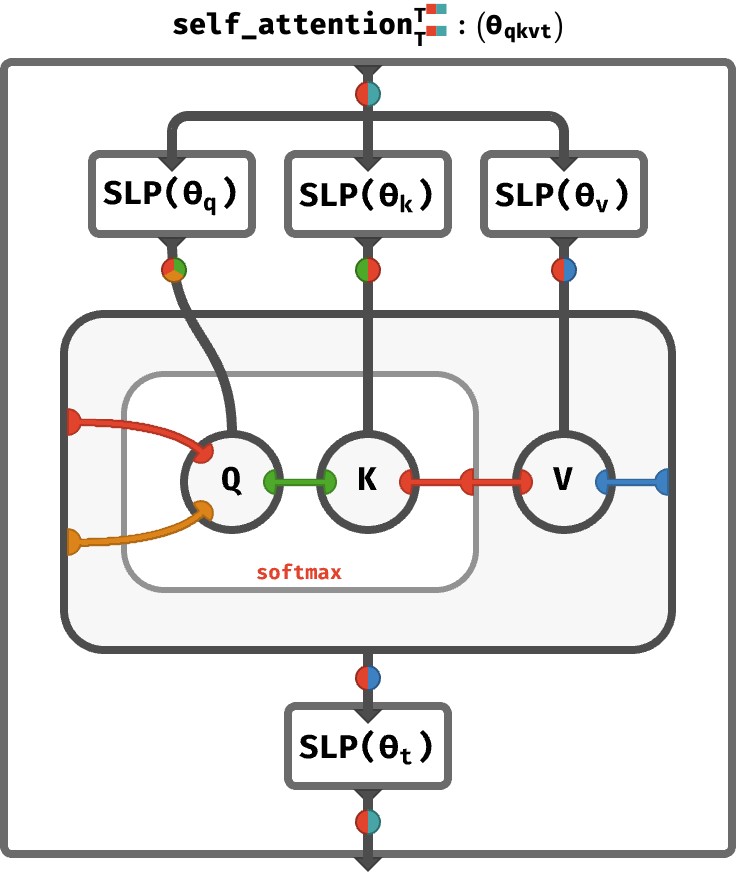
If anyone is interested in a kind of tensor network-y diagrammatic notation for array programs (of which transformers and other deep neural nets are examples), I wrote a post recently that introduces a kind of "colorful" tensor network notation (where the colors correspond to axis names) and then uses it to describe self-attention and transformers. The actual circuitry to compute one round of self-attention is remarkably compact in this notation:
{kind=link}