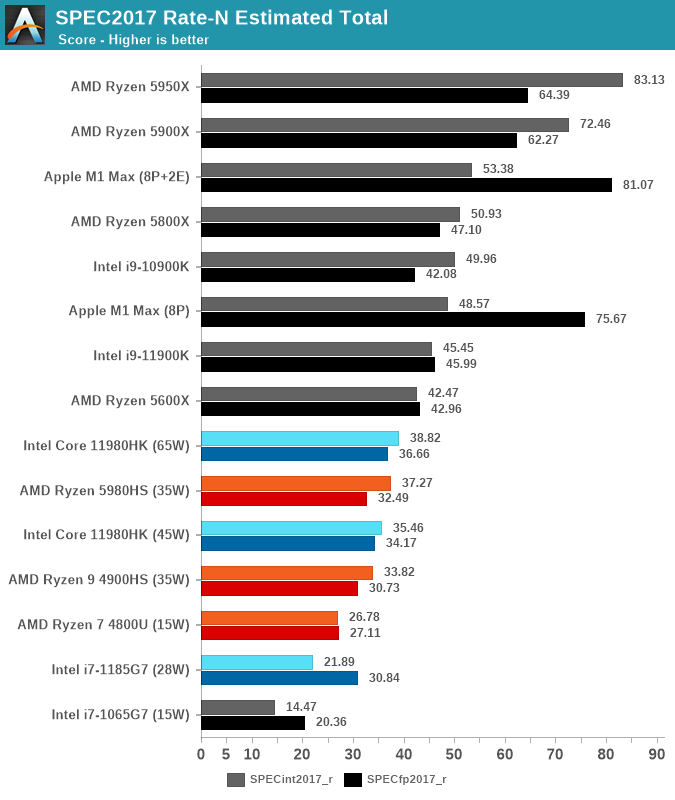
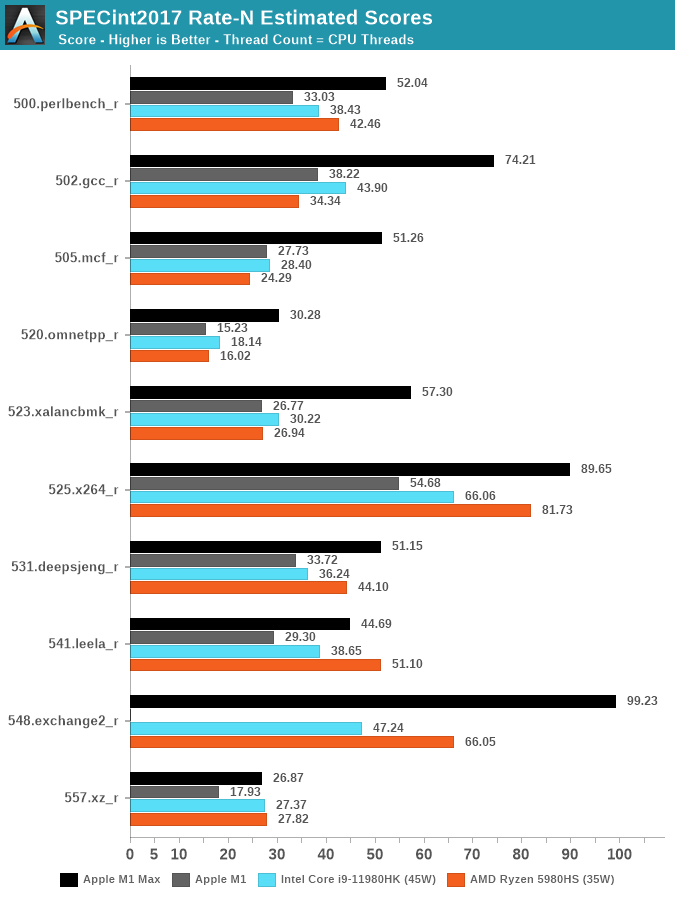
| Of course IPC needs to be contextualized, but it's still a very important metric. And Intel's processors aren't clocked 3x higher than Apple either - that would be 9 GHz, and you can't even sustain 5 GHz all-core at 35W let alone 9 GHz which just isn't physically possible even on LN2. https://images.anandtech.com/graphs/graph17024/117496.png That's an absolutely damning chart for x86, at iso-power the M1 Max scores 2.5x as high as a 5980HS in FP and 1.43x as high in integer workloads, despite having just over half the cores and ~0.8x the transistor budget per core. So it's a lot closer to the ~2.5-3x IPC scores than you'd think just from "but x86 clocks higher!". And these results do hold up across the broad spectrum of workloads: https://images.anandtech.com/graphs/graph17024/117494.png Yes, Alder Lake does better (although people always insist to me that Alder still somehow "scales worse at lower power levels than AMD"? That's not what the chart shows...) but even in the best-case scenario, you have Intel basically matching (slightly underperforming) AMD while using twice the thread count. And that's a single, cherrypicked benchmark that is known for favoring raw computation and disregarding performance of the front-end, if you are concerned about the x86 front-end, this is basically a best-case scenario for it... high code compactness and extremely high threadability. And it still needs twice the threads to do it. https://i.imgur.com/vaYTmDF.png Like your "but x86 uses higher clock rates", you can also say "but x86 uses SMT", so maybe "performance per thread" is an unfair metric in some sense, but there is practical merit to it. If you have to use twice the threads to achieve equal performance on x86 then that's a downside, where Apple gives you high performance on tasks that don't scale to higher thread counts. And if Apple put out a processor with high P-core count and without the giant GPU, it would easily be the best hardware on the market. I just strongly doubt that "it's all node" like everyone insists. Apple is running fewer transistors per core already, and AMD/Intel are not going to double or triple their performance-per-thread within the next generation regardless of how many transistors they might use to do it (AMD will be on N5P this year, which will be node parity with Apple A15). x86 vendors can put out a product that will be competitive in one of several areas, but they can't win all of them at once like Apple can. And going forward - it's hard to see how x86 fixes that IPC gap. You can't scale the decoder as wide, Golden Cove already has a pretty big decoder in fact. A lot of the "tricks" have already been used. How do you triple IPC in that scenario, without blowing up transistor budgets hugely? Even if you get rid of SMT, you're not going to triple IPC. Or, how do you triple clockrate in an era when things are actually winding backwards? Others are very, very confident this lead will disappear when AMD moves to N5P. I just don't see it imo. The gap is too big. |
{kind=link}
{kind=link}
{kind=link}