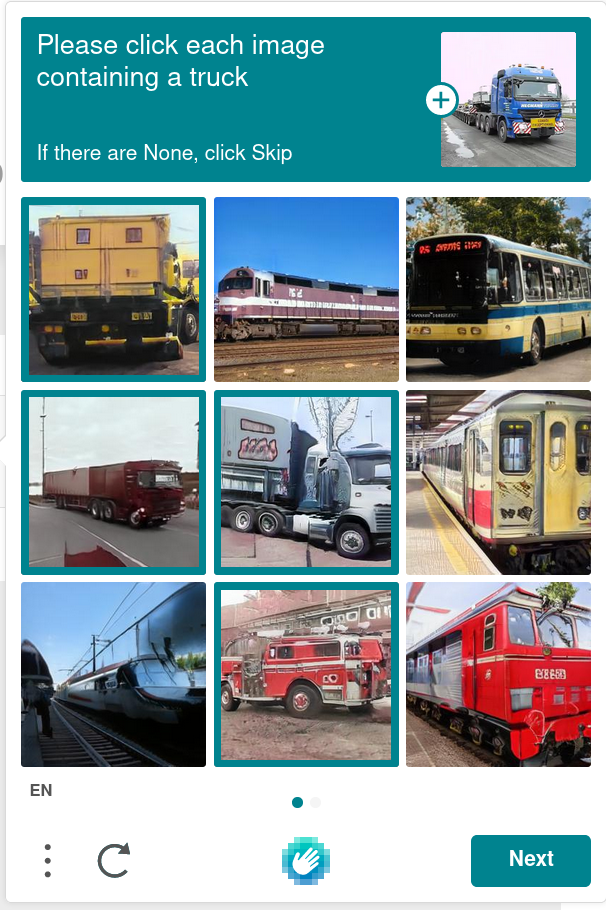
Other commenters have talked about labelling. Maybe labelling of real life data is something they're trying to do; but from my experience with hCaptcha the challenges are _NOT_ real life data. They're AI-generated images which bear a passing resemblance to the targets but if you look closer nothing adds up at all.
For many generative models, this is on the way to become a standard- using Humans as a judge of generated material, and this is not limited to Computer Vision either. I am about to use this technique to judge the sanity of text generated by a Transformer model for a paper that I am writing (with a small group).
There are also attempts to properly standardize it, and this is called- HYPE [0]. And there are big names like Fei-Fei Li and Michael Bernstein behind it.
Not sure they are fooling anyone. It's more like "is our generated image good enough to make a human recognize what it is to get rid of an annoying pop up?". If there were actually consequences to getting it right/wrong people would pay more attention I'm sure.
Exactly. That is another way to improve accuracy once you have done it ”in a regular” way already. You can look for synthetic image generation and it’s benefits on model accuracy and optimization.
The broken images to me look like instances where two or more cameras or images were used and then stitched together. Probably also done while the camera and object are moving making it more likely to be wonky.
No way. The letters/writing look exactly like mirrored GAN output. That's not what would happen with blur or stitching together (there would be no mirroring symmetry or all the '8' letters), or with synthetic 'machine teaching' datapoints either (as far as I've ever seen). Look at the cat StyleGAN sometime if you don't know what I'm talking about.
Which leaves me wonder what the point is. If you are generating GAN images per CIFAR or ImageNet class, you know what the label is and don't need to label it. Perhaps they just generate lots of images to fill up the pipeline for the CAPTCHAs, to avoid reuse which could be exploited by spammers, when they have too little paying work?
I think that might be something they actually do. Lately it happened to me see pictures of boats on land, bicycles merged with surrounding objects, weird proportions, and usually those strange images are extremely pixelated with those strange reddish or greenish fluo pixels that appear on generative network images.
But other times the pictures are 100% real life images.
Very nice. It looks like some sort of training to defend against bots that can currently pass hCaptcha..? If so, I wonder how long that particular arms race can last.
I've not seen anything like this in the wild. And.... well, now I'm curious about how you had these examples to hand. When and why did you start collecting them?
{kind=link}
{kind=link}
{kind=link}
{kind=link}