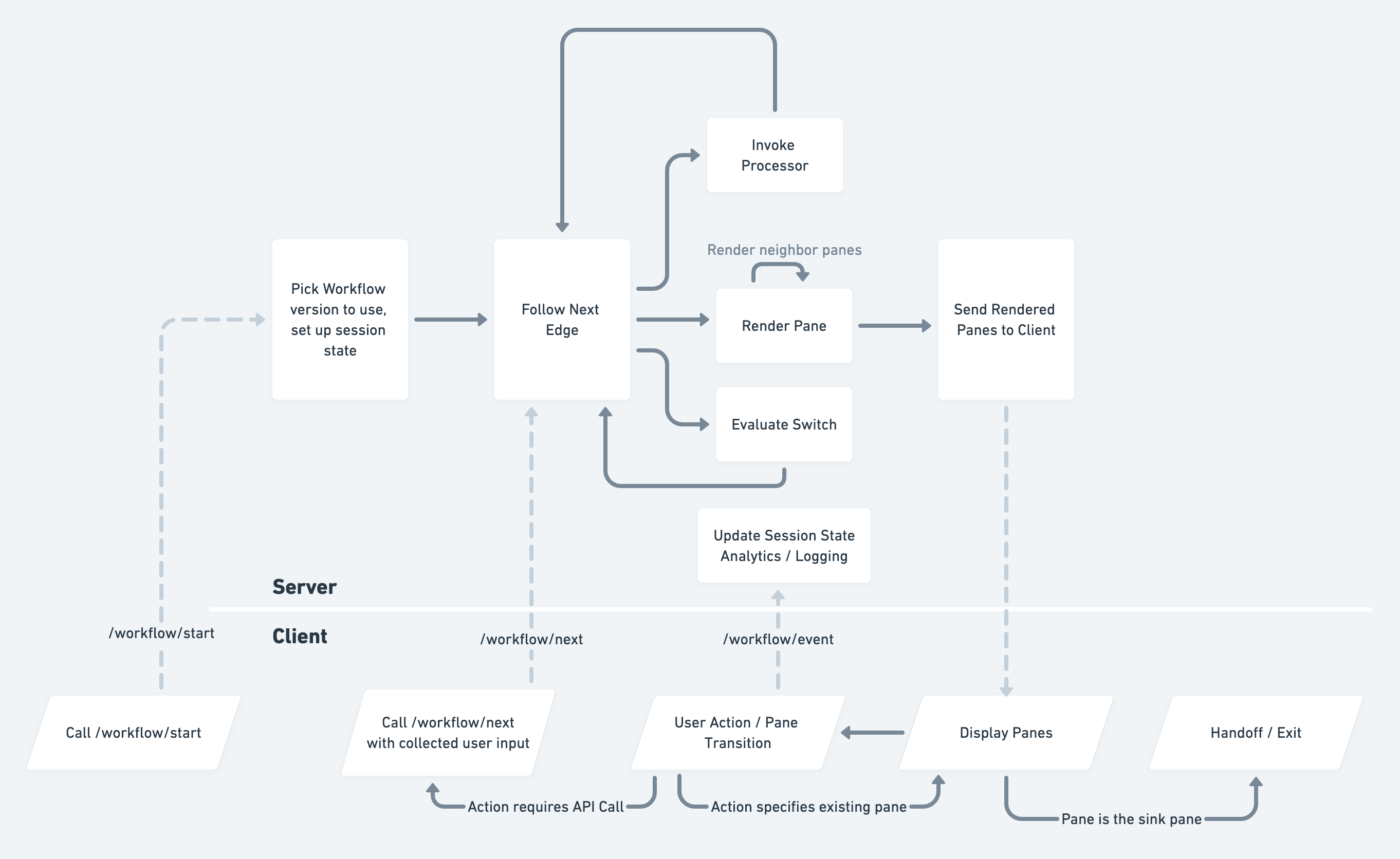
| > 1. How you implemented this on the backend? Did you consider using something like Temporal, AWS Simple Workflow, or AWS Step Functions? Given this already a major change in our client<>server interaction model and that we didn't want to _fully_ rewrite the entire world, we didn't consider additional major changes to our existing backend services strategy (Go services + RPC) as part of this project. We had a bunch of backend logic and common code we wanted to reuse across Flex Link and the legacy endpoints, which gives us a stepwise mechanism for future refactors once the old APIs are turned down. Once this rolls out to 100%, the new API boundaries do allow us to refactor the backend into something more like you suggest — leveraging step functions, lambdas etc if desired. > 2. Interested in how you're avoiding (waiting) on network calls on each action. You mentioned it was coming in next post. Yes! Full details of that would take a dedicated post. However, if you look at the "Client Rendering Loop" diagram in the post ( https://images.ctfassets.net/zucqsg1ttqqy/5kp6LibAllW1YW69jT... ) you'll see there is a "render neighbor panes" loop in the flow. At the point where we've walked the graph and encountered a pane, we can do a quick breadth-first-search to render out neighboring panes (that don't have a processor in between) and serve those all to the SDK. We all them "additional panes". The response includes a map from "action" to "additional pane" so the SDK can know whether to hit the API or use an already-provided additional pane. (this is in the diagram as well) The nice part is, clients don't _have_ to implement this functionality. They can always hit the server each time they want the next pane. But as a performance optimization they can leverage the additional panes to render many things locally. > 3. How are you managing multiple workflows? Does a common child graph make sense for a common workflow? We use the expanded semantic versioning in the post for teams to have their own versioned workflow namespace. On the `workflow/start` call, we have a dispatcher that can pick which workflow to serve based on the provided configuration, SDK version, platform, experiments, etc. We don't yet support subgraphs for common chunks of a workflow but it is definitely in our roadmap and would allow teams to share common pieces of the graph. |
{kind=link}
How is session state kept? Is /event required (as data would be sent in /next?).
Also as I understand, Processors won't be involved until they are needed. E.g. if we have 2 panes but only the result of the first was required to be processed, would the processor be invoked after just the first pane was complete?