|
|
|
|
|
|
by ska
1963 days ago
|
|
|
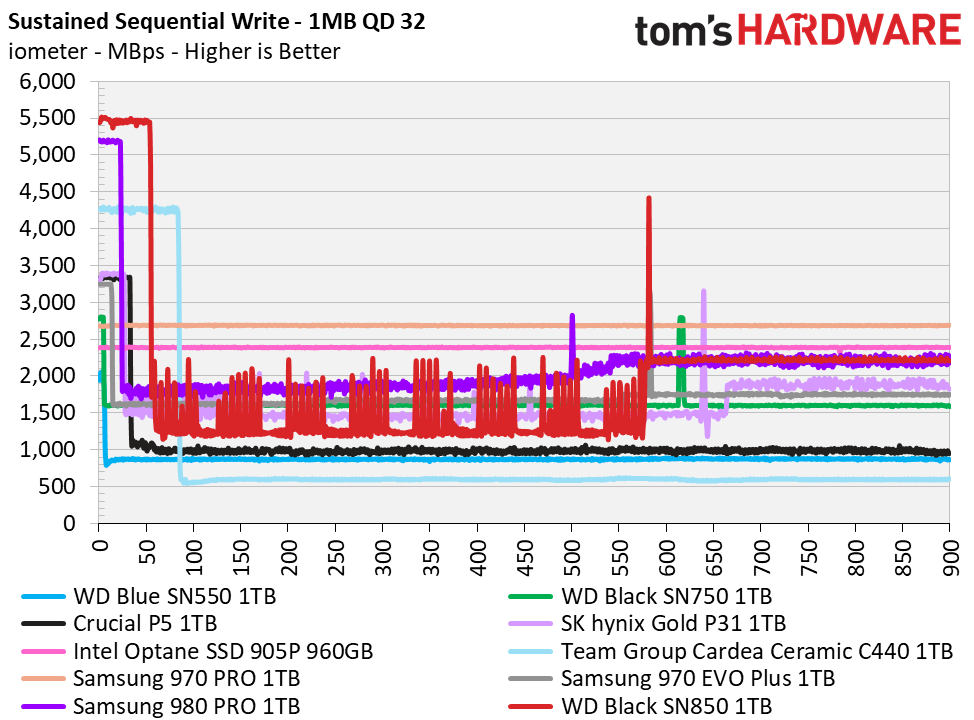
I suspect the biggest (build time) benefit to most c++ workflows and toolchains was the move to ubiquitous SSD. Prior to that in my experience excepting expensive RAID array dedicated build machines, it was really easy to build a system that would always be IO bound on builds. There of course were tricks to improve things but you still tended to hit that wall unless your CPUs were really under spec. edit: to be clearer, I'm not thinking of dedicated build machines here (hence RAID comment) but over all impact on dev time by getting local builds a lot faster. |
|
|
{kind=link}
Source code files are relatively small and modern OSes are very good at caching. I ran out of SSD on my build server a while ago and had to use a mechanical HDD. To my surprise, it didn’t impact build times as much as I thought it would.