|
|
|
|
|
|
by tarlinian
2132 days ago
|
|
|
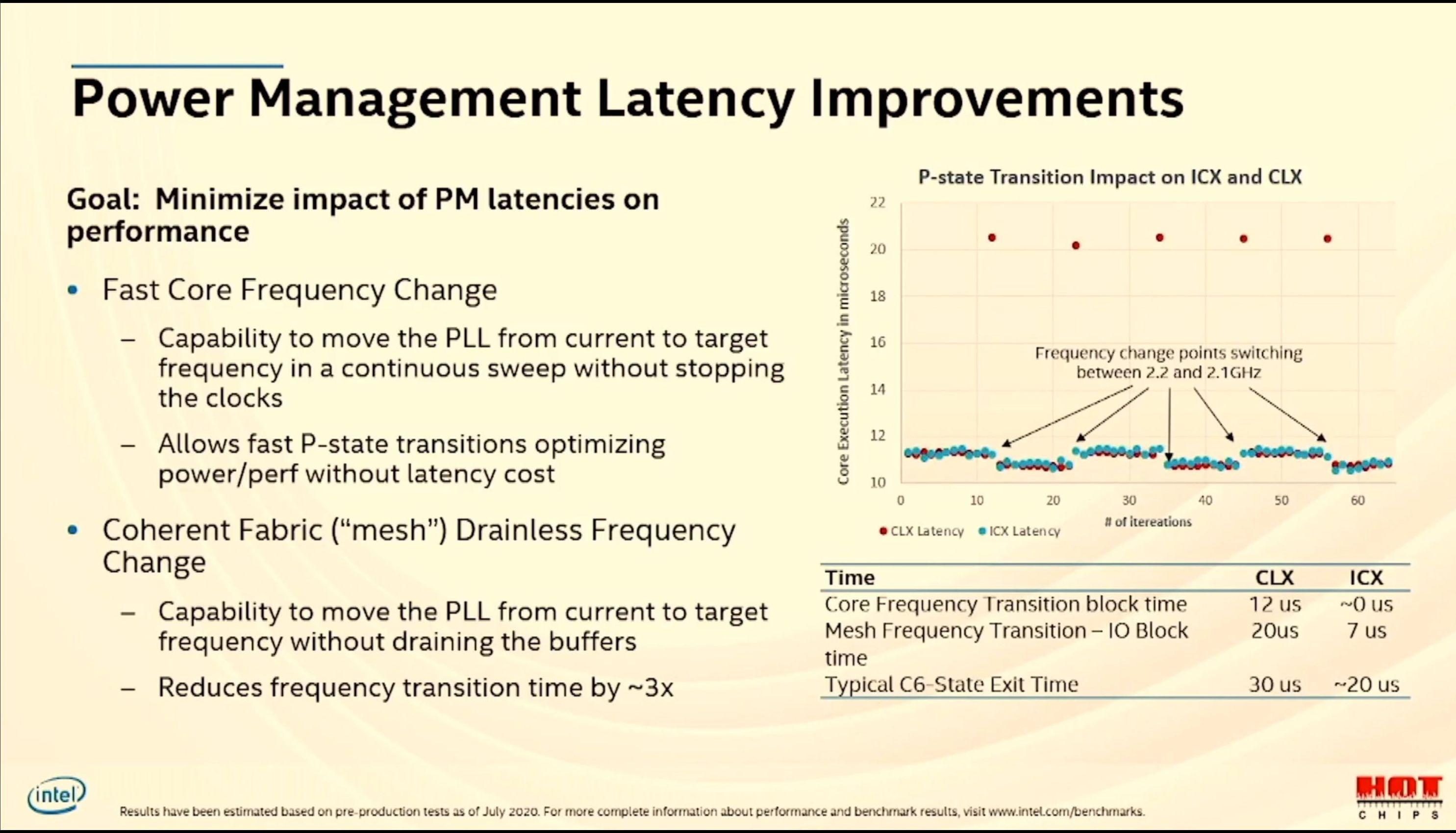
This isn't the real problem though...the problem with the existing AVX-512 implementations is the "relaxation time" causes subsequent scalar code to be slow. From later in the same post: > Here, we have the worst case scenario of transitions packed as closely as possible, but we lose only ~20 μs (for 2 transitions) out of 760 μs, less than a 3% impact. The impact of running at the lower frequency is much higher: 2.8 vs 3.2 GHz: a 12.5% impact in the case that the lowered frequency was not useful (i.e., because the wide SIMD payload represents a vanishingly small part of the total work). Interestingly enough, this is another feature that is supposed to have been improved on server Icelake. The frequency transition halt time is now pretty much negligible. The "core frequency transition block time" goes from ~12 us on CLX (similar to the number quoted above) to ~0 us on ICX. (Slide with frequency transition info: https://images.anandtech.com/doci/15984/202008171754441.jpg) |
|
|
{kind=link}