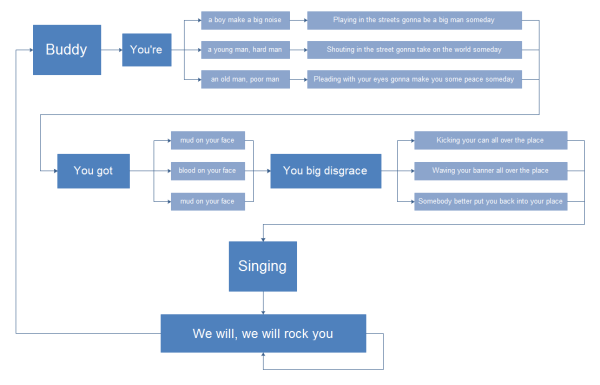
...because if they did, they might realize that some of their favorite structures are a hot mess. Seeing things in a new way often leads to learning, which a good developer would welcome. Personally I can't remember the last time I used an actual flowchart, but I do use state machines. Sometimes I'll go through an exercise of re-casting complex logic as a state machine. Often, that leads to a realization that making the state machine explicit would yield far more testable and maintainable code than leaving it in its more common if/loop/nested-function form.
> ...because if they did, they might realize that some of their favorite structures are a hot mess.
They may only be a hot mess when expressed as a flowchart. But so what? I'm not programming in flowcharts. If exceptions can do what I want cleanly, why do I care if it's a mess considered as a flowchart? That's not my problem.
This argument is like saying that the library function I call is a mess of a flowchart. Why should I care? Can I express what I need to express cleanly by calling that function, or not?
Of all the arguments against exceptions, "it's got a mess of a flowchart" is the absolutely least relevant one.
The flow charts in the link represent control flow. Compiler optimizations are, in part, constrained by their ability to map and statically determine control flow. So I think it is a grave mistake to say that something having a ‘mess of a flowchart’ is the least relevant concern about some PL construct. The implication that a flowchart representation offers nothing to a programmer, implies that the performance characteristics of your code does matter to the programmer. So sure, in some application domains (although I don’t think there are any) performance may take a backseat to performance and efficiency, this information is useful and can very well illustrate the pitfalls and trade offs of using certain constructs in code.
I'm pretty much never worried about the performance of the "exception taken" case. The compiler can be really quite inefficient there before I have any reason to care.
There are places to worry about compiler efficiency. I don't think that this is one of them.
Statically determining data flow is just as important, since it means being able to parallelize your code. Flowcharts are a very limited tool, other diagramming approaches (such as proof nets) can generalize on them in a helpful way.
>they might realize that some of their favorite structures are a hot mess
Normal brain: Find the representation that best expresses the structure to discover the hidden simplicity in everything.
Galaxy brain: Use flowcharts to draw out how exceptions work, forget your previous understanding, and then realize that they are too complicated for anyone to use.
I strongly agree that multiple ways to look at things is good.
Programming languages have different "things" built in. Like, if you have re-entrant function calls, then your language has a built-in data structure called "the stack".
If you have some algorithm that needs a stack, you have the choice of using the built-in stack, or using an explicit stack.
If you have a programming language with some sort of type system, then you have tagged data built-in. You can model your domain in the type system, or you can model your domain using a tuple like (tag, datablob).
If you have object-oriented programming with dynamic (single) dispatch on the first argument, then your language somewhere has a built-in data structure called a table/dictionary/associative-array. If you want to implement some sort of switching behavior you can do a switch on the `tag`, or encode the tag in the type system, and use dynamic dispatch.
Some programming languages have support for asynchronous calls. That programming language has a built-in scheduler of sorts. You can use it, or build your own, (or use the OS!).
A state machine, I think, is a great example of the same idea. Your CPU has a bunch of state (e.g. the program counter), and your programming languages has a bunch more state (like the current stack frame, the line number). You can encode your state machine in that, or you can model it explicitly. How well you can do it "implicitly" depends on other language features, like whether you have coroutines.
I think it's challenging, without expertise that might come only from having solved an identical problem already, to know ahead of time when to use these built-in things or roll your own. When you mention testing, I think that's a great example of expertise you've acquired. If you would like to test certain invariants in your state machine, e.g. "a transition from A to B never happens", then you're going to have a hard time doing so if your state machine's state is encoded in the line number of your language interpreter or the program counter, or whatever.
Describing the mess in a not-messy way is the whole point of exceptions. If you have a mess in your code either clean it up or document it, don't hide it.
- - - -
Sometimes the problem you're solving really does require a gnarly flow-chart. If that's the case, you're almost certainly better off writing (and documenting!) a state machine instead.
If your control-flow graph is only a little gnarly then representing it with exception syntax is fine IMO (I write Python code too, with exceptions.)
The problem comes when you accidentally create a hidden gnarly graph (as the result of bad design up front, or "drift" over time as a piece of code gets reworked, maybe by multiple people who may not all be privy to the whole history of the design and code, or both) and then forget to do something crucial along some flow of control and you have a hard-to-debug bug.
> I can't imagine writing Python without try blocks...
In other words, Python requires that model, but making something necessary isn't the same as it being good. If you go around breaking people's arms then splints and casts become necessary. Does that make arm-breaking OK?
> It allows you think about the problem with a much smaller cognitive load.
There's a very fine line between "smaller cognitive load" and "sweeping stuff under the rug". Since you mentioned Python, I'll point out that a lot of Python code only looks simple because it's incomplete and will fail catastrophically for what should be innocuous errors. Add the proper error handling and it's just as complex as code using an error-return or optional-type model. Often that means even more cognitive load because the happy path and the handlers are in multiple methods/classes/files (especially likely as multiple people hack on code over time).
This is essentially the point I made in a comment above, these representations are valid considerations for a programmer to weigh when selecting abstractions and constructs to implement some functionality. But it seems like very few people agree.
Paul Lamere from The Echo Nest made an awesome music analysis demo called "The Infinite Jukebox" (for when your favorite song just isn't long enough), for automatically finding loopable points in music. And it can use that analysis to stretch a song out to any duration you want, by seamlessly skipping and looping parts of it to shorten or stretch it. It's interactive, so you can point and click on the arcs to control how it loops at any point.
For when your favorite song just isn't long enough
This web app lets you upload a favorite MP3 and will then generate a never-ending and ever changing version of the song. Infinite Jukebox uses the Echo Nest analyzer to break the song into beats. It plays the song beat by beat, but at every beat there's a chance that it will jump to a different part of song that happens to sound very similar to the current beat. For beat similarity the uses pitch, timbre, loudness, duration and the position of the beat within a bar. There's a nifty visualization that shows all the possible transitions that can occur at any beat. Built at Music Hack Day Boston 2012.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}