|
|
|
|
|
|
by sairahul82
2499 days ago
|
|
|
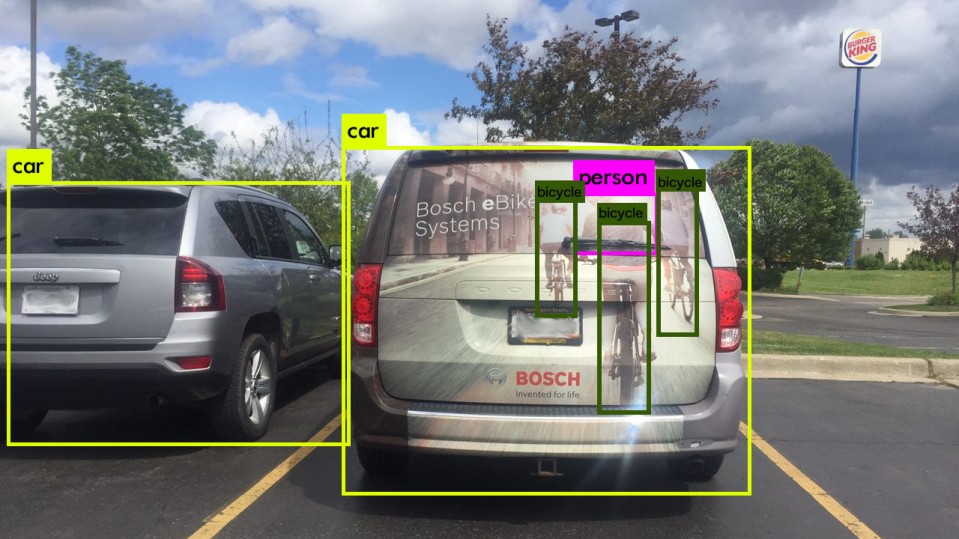
The first thing we need to remember is the self driving doesn't work like our brain. If they do then we don't need to train them with billions of images. So the main problem is not just building the 3d models. For example we don't crash into the car because we never seen that car model or that kind of vehicle before. Check https://cdn.technologyreview.com/i/images/bikeedgecasepredic... we never think that there is a bike infront of us. Humans do lot more than just identifying an image or doing 3d reconstruction. We have context about the roads, we constantly predict the movement of other cars, we do know how to react based on the situation and most importantly we are not fooled by simple image occlusions. Essentially we have a gigantic correlation engine that takes decision based on comprehending different things happening on the road. The AI algorithms we teach does not work in the same way as we do. They overly depend on the identifying the image. Lidar provides another signal to the system. It provides redundancy and allows the system to take the right decision. Take the above linked image for an example. We may not need a lidar once the technology matures but at this stage it is a pretty important redundant system. |
|
|
{kind=link}
That's not relevant when discussing which technology to use to build the 3d models. Everything you said is accurate until the last few sentences. Lidar provide the same information (line of sight depth) as stereo cameras, just in a different way. The person you're responding to is talking about depth from stereo, not cognition.