|
|
|
|
|
|
by yomritoyj
2932 days ago
|
|
|
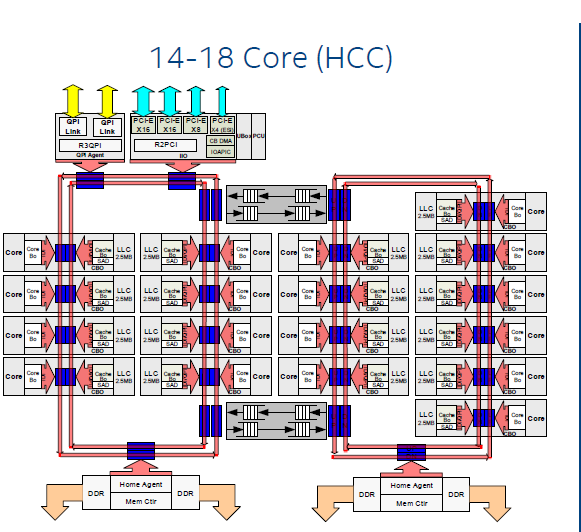
As an outsider to 'enterprise-grade' computing, I'm curious about situations where a high number of cores in a single processor would be superior to multiple processors with the same total energy draw sitting on a single motherboard? I can understand HPC applications where the high-speed interconnect on the chip would make a big difference. But in business applications where the cores are dedicated to running independent VMs, or are handling independent client requests, what is really gained? There would still be some benefits from a shared cache, but how large quantitatively would that be? |
|
|
{kind=link}