|
|
|
|
|
|
by SomeCallMeTim
3698 days ago
|
|
|
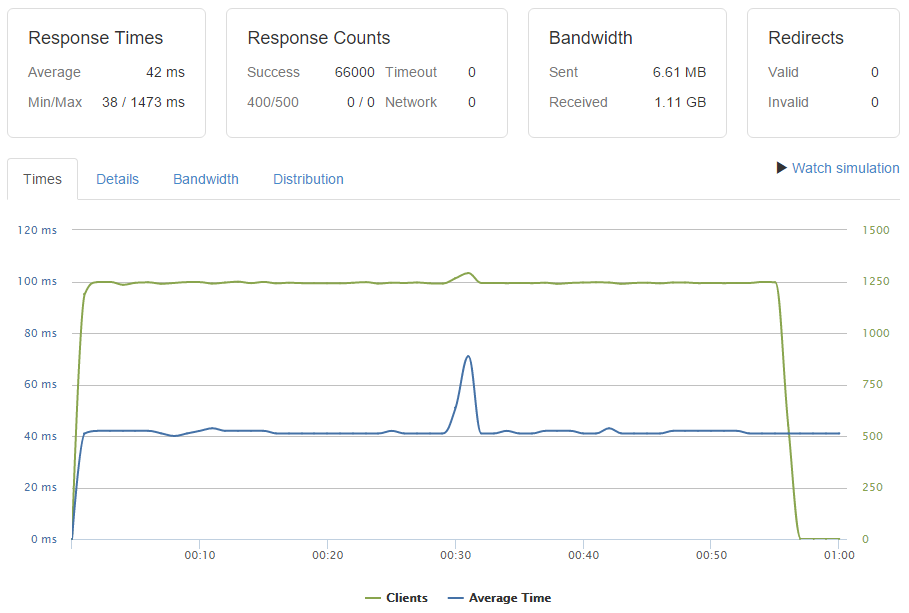
I was shocked that 12 requests/second could take down any site. I use async logic (previously OpenResty, more recently NodeJS and Go) and largely pregenerated sites, so 2500 requests/second is a minimum baseline -- on a much lower end instance than an m4.xlarge. There's a reason I don't use PHP (or any primarily synchronous language like Ruby) any more. |
|
|
{kind=link}