Really cool article. Posts like this always make me wonder what the state of the programming would be if browsers hadn't sucked up almost all of the world's compiler optimizers.
Look at what Mike Pall did with LuaJIT2 - I assume if the world wasn't so focused on the web, we would see more of it in other languages. But really, things aren't that bad. Microsoft has enough good people working on RyuJIT, PyPy has some of the best people advancing metatracing JITs, and Mike Pall is a god among men.
But considering that optimized scalar code performance has moved, what, maybe 40% over the last two decades, I'm going to say "not much". Compilers are sexy, but they're very much a solved problem. If we were all forced to get by with the optimized performance we saw from GCC 2.7.2, I think we'd all survive. Most of us wouldn't even notice the change.
I'd disagree. Classical compiler work is very mature, yes - and new progress in things like register allocation and backend IR-based optimization stuff is well trod ground.
But in the context of JIT compilers for dynamically typed languages, in particular the space involving runtime inferred hidden type models, there is a TON of work left on the table.
It hasn't been paid much attention to in academia, IMHO largley because of a historical perspective on optimizing dynamic languages as "not classy" work among language theorists. I hope that perspective changes over time.
> Compilers are sexy, but they're very much a solved problem.
Not for all of the other widely-used languages that still have incredibly simple interpreters. Think how much energy could have been saved if Ruby, Python, and PHP were all as fast as your average JS engine.
Ruby has massive adoption, as do Python and Perl and PHP. Environments with objectively better performance like the JVM and .NET have not, in fact, done all that well comparatively in this environment (which is to say they've done fine too and achieved "massive" adoption, just not that much better than their slower competitors).
In fact, looking at the market as it stands right now I'd say that performance concerns are almost entirely uncorrelated with programming environment adoption.
Considering the massive speed improvements we have been seeing in Javascript, but also languages like Ruby, I'd say compilers is a solved problem for staticly compiled languages, but perhaps not as much for interpreted highly expressive languages.
ajross is right. People choose the languages they like regardless of performance.
JS perf is important to users though. Faster execution means fewer watts spent rendering and interacting with your favorite web page.
(Fun fact: B3's backend contains a machine description language that gets compiled to C++ code by a ruby script, opcode_generator.rb. We use Ruby a lot.)
And Go proves munificent's point: it doesn't have many compiler optimizations either. (This may change with the WIP SSA backend, but the point remains that Go gained huge popularity in spite of having a non-optimizing compiler.)
Yeah, more interesting is having them rediscovering Turbo Pascal compile speeds.
EDIT: I wonder why the positive effect to re-discovering that not all compilers need to be like C and C++ compile speeds and that it was once upon a time mainstream, is worthy of downvotes.
Are you claiming Go runs at the speed of Ruby/Python/PHP etc? Because from what I read, migration to Go from above mentioned language led to lot of hardware / memory saving.
I'd think Java can certainly be considered having highly optimized compiler / runtime. But it has almost same performance as Go and much higher memory usage compared to Go.
Compilers are sexy, but they're very much a solved problem.
This may be true for sequential languages, but is very much false for the compilation of concurrency and parallelism. It's basically not known how to do this well. Part of the problem is that CPU architectures with parallel features have not yet stabilised.
For sequential languages the problem has shifted: how can I get a performant compiler easily. The most interesting answer to this question is PyPy's meta-tracing, and that's work is from 2009, and far from played out.
> optimized scalar code performance has moved, what, maybe 40% over the last two decades
I'm not convinced. Raw single-thread number crunching performance is somewhere around _two to three fold_, clock-for-clock, on Intel x86, over that of 10-15 years ago. What methodology do you use to attribute only a fraction of those gains to language optimizers? And even if you are correct, why is it meaningful? Who is going to have invested energy in optimising the shit out of mundane codegen when hardware performance will have just come and stolen your thunder a few months later?
The problem we have now is that CPUs are gaining ever more complex behaviour, peculiarities, and sensitivities. I'd say compiler engineering is far from a "solved problem", even for statically-typed languages.
> The problem we have now is that CPUs are gaining ever more complex behaviour, peculiarities, and sensitivities.
With mainstream CPUs, exactly the opposite is happening. CPUs are getting more complex under the hood, but less sensitive to code quality. For example, a lot of the scheduling hazards in the P6 microarchitecture have been eliminated in subsequent iterations. Branch delay slots are a thing of the distant past, so are pipeline bubbles for taken branches, indirect branch prediction is extremely capable, even the penalty on unaligned accesses is minimal.
Well, sure, but SIMD more than compensates for all of that, given how hard autovectorization is. In fact, I think with things like AVX and NEON becoming ubiquitous, you can get more benefit out of writing in assembly (or intrinsics) than any time I can think of in the past 10 years.
> Compilers are sexy, but they're very much a solved problem
No they're not, and won't be for long (ever?). However it does not matter because they are "good enough".
Compilers are driven by heuristics which provide "reasonable" results in most cases for common architectures. But they still leave a lot on the table. Compiler writers have to trade compile-time with execution-time.
Now we're not talking about an order of magnitude, but rather ~20%-30% in some workloads. When it matters (I guess for people like Google/Facebook/Amazon/... it translates in electricity bill and a number of racks to add to the datacenter) people may have to get down to the assembly level for a very small (and hot) part of the program.
That seems a bit chicken-and-the-egg-y though: if the web didn't become a global phenomenon then there would be far less interest in improving the browsers, far less business need for programmers, and far fewer people working on whatever they'd be working on if they weren't working on browsers.
They're solving a non-issue. The rest of the world is perfectly fine with the statically typed, well designed languages that are easy to compile. And only the web world is so obssessed with smart compilers compensating (impressively, but still far from being sufficient) for multiple deficiencies in the language design.
> The rest of the world is perfectly fine with the statically typed, well designed languages that are easy to compile.
Python, Ruby, PHP, and Perl aren't "the rest of the world"? As far as compilers are concerned, all of those languages have more troublesome semantics than JavaScript does.
> And only the web world is so obssessed with smart compilers compensating (impressively, but still far from being sufficient) for multiple deficiencies in the language design.
You have no idea how much compilers have to compensate for the deficiencies in C and C++'s design.
Nobody really cares about their performance. They're just fine with their simple interpreters. Web is different, there is no choice, no fallback to C.
And no, thank you kind sir, but I've got a very good idea of what compilers are doing wrt. C deficiencies, I was writing OpenCL compilers for 6 years at least. Besides aliasing stupidity and byte-addressing there is nothing really bad to compensate for.
> Web is different, there is no choice, no fallback to C.
asm.js and Web Assembly.
> Besides aliasing stupidity and byte-addressing there is nothing really bad to compensate for.
Aliasing issues, C++ heavy reliance on virtual methods, too many levels of indirection in the STL, overuse of signed integers due to "int" being easier to type interfering with loop analysis, const being useless for optimization, slow parsing of header files...
For example in JS, once you prove that "o.f = v" is not going to hit a setter (or you put a speculative check to that effect), then you know that this effect does not interfere with "v = o.g" (provided you check that it's not a getter). JS VMs are really good at speculating about getters and setters. The result is that alias analysis, and its clients like common subexpression elimination, are super effective. It's only a matter of time before we're creating function summaries that list all of the abstract heaps that a procedure can clobber so even a function call has bounded interference.
This is totally different from C. There, making sure that accesses to o->f and o->g don't interfere is like pulling teeth. And the user can force you to assume that they always interfere by using -fno-strict-aliasing, which is hugely popular.
The fallback-to-C paths on the web aren't that great, though. At least not yet. Once you fall back to C, you're sandboxed into a linear heap with limited access to the DOM and JS heap. But we'll fix that eventually. :-)
Web Assembly is not even there yet, asm.js up until recent was more a toy and a standalone runtime, I have not seen it being routinely used for a fallback, nothing like, say, python with C modules.
As for virtual methods, it is a problem of a bad C++, devirtualisation may help, but nobody cares in general. We have a cool curiously recurring template pattern instead.
But for the integers you're right. And signedness is still the most annoying source of bugs in the infamous LLVM instcombine.
Headers are a frontend issue, nothing to do with the optimisations.
Re: int, isn't it the reverse? I.e. don't compilers find loops using ints easier to optimise because they can assume the counter does not wrap?
Also, what do you mean by level of indirection in the STL? Pointer chasing or, I suspect, layers of layers of tiny functions that need to be inlined for reasonable performance?
> statically typed, well designed languages that are easy to compile
Which ones are these? All of the statically-typed and well-designed languages I can think of are, at the least, hard to compile well, if not hard to compile in the first place. (Haskell and Rust both come to mind; there are few Haskell compilers other than GHC, and no Rust compilers other than rustc.) The languages that are easier to compile are either not statically-typed in a useful way, or not well-designed, or both.
I've never heard anyone say Ada was easy to compile. Also, I heard its uptake was slowed by how hard it was to get the early compilers working. So, where did you see an easy one? Seriously, because Ada still needs a CompCert (or at least FLINT) style certified compiler. An easy Ada compiler would be a nice start on that.
I always thought that Ada was easy to compile in the backend (i.e. the moral equivalent of what B3 does) but challenging on the frontend because of how large the language is. Could be wrong though.
The frontend is usually the hard part IMO. In WebKit, we have 100,000 lines of code for our "frontend" (i.e. the DFG compiler) and 50,000 lines of code for our "backend" (i.e. B3). That split is really interesting.
You can't compile Rust without types and inside functions, most types come from inference and coercions, so "type checking" is really "type resolution".
> Rust (and Haskell) is not easy to _type-check_ though.
Is that really the case? It seems to me that a Prolog-like resolution system, coupled with a constraint solver, would get most of the job done with little effort.
There are certainly many rules to keep track of, but in some cases the newer rules are strict generalisations of the older rules. For example, Haskell's original type classes are just a special-case of modern multi-parameter, flexible instances/contexts, etc. type classes. Likewise, we can implement constraint kinds, type class instance resolution and type equalities using one constraint solver.
I don't understand this perspective. Is the point that JavaScript just works such that you don't have to worry about it compiling at runtime?
To me this is the difference between knowing that your program will probably work after it compiles, vs not knowing until after its deployed.
What I think people really enjoy in dynamic languages like JavaScript is the instant feedback, just reloading the browser. This can be accomplished with decent IDEs for most statically typed languages.
While they have sucked up a lot, it is far from certain all would have been employed optimizing compilers if that hadn't happened. Demand tend to create the supply.
Also, many of the improvements done for JS will certainly trickle down to Python, Ruby, PHP eventually.
Good to see the Webkit team (mostly Apple) continue putting serious energy into JS performance. Take a bit of guts to throw out the whole LLVM layer in order to get compilation performance...
It's also encouraging to see them opening up about future directions rather than just popping full-blown features from the head of Zeus every so often. (Not that they owe us anything... ;-)
(Edit: it's also damned impressive for 2 people in 3-4 months.)
As Phil said, the development cost was not that high all things considered. But even if it was - think about the number of user-hours that 5% is leveraged across, and the resulting time savings and battery life savings for those users. It would be worth investing even more than we did for 5%!
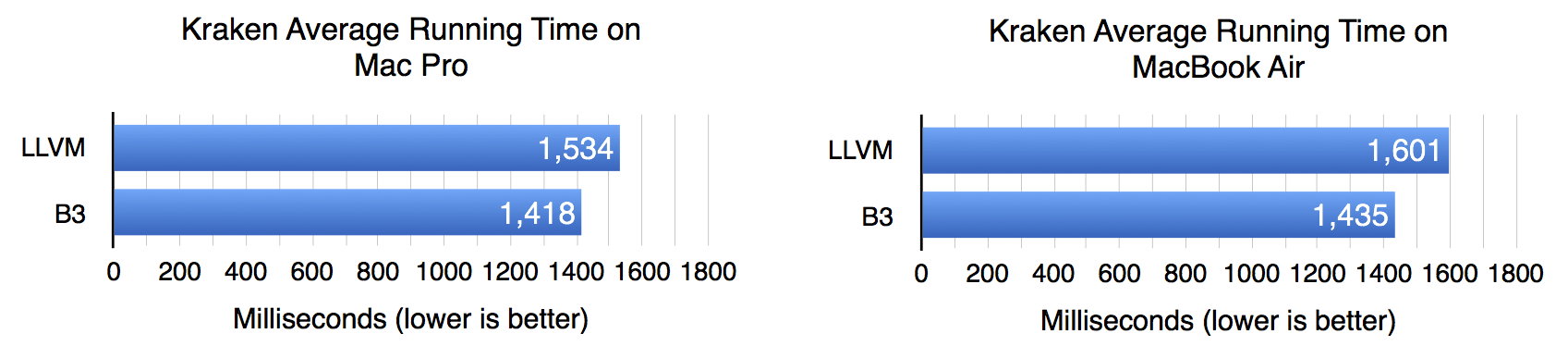
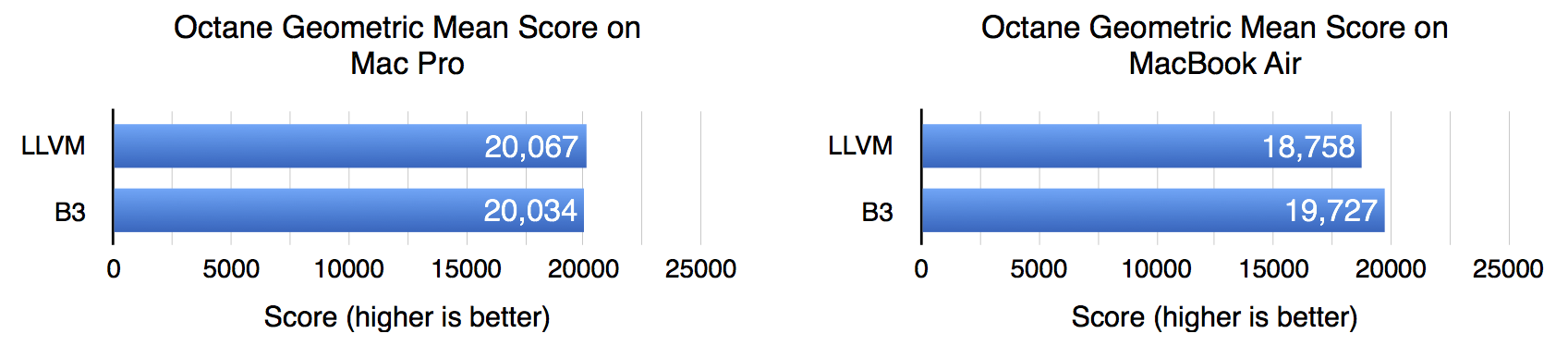
tl;dr: B3 will replace LLVM in the FTL JIT of webkit. LLVM isn't performing fast enough for JIT mainly because it's so memory hungry and misses optimisations that depend on javascript semantics. They got an around 5x compile time reduction and from 0% up to around 10% performance boost in general.
I think that's mostly accurate, in the sense that we wouldn't have done this if it was only motivated by specializing for JavaScript semantics. We had gotten pretty good at having our high-level compiler (DFG) burn away the JavaScript crazy and leave behind fairly tight code for LLVM to optimize.
But as soon as we realized that we had such a huge compile time opportunity, of course we optimized the heck out of the new compiler for the kinds of things that we always wished LLVM could do - like very lightweight patchpoints and some opcodes that are an obvious nod for what dynamic languages want (ChillDiv, ChillMod, CheckAdd, CheckSub, CheckMul, etc).
But isn't it true that some of the things you ended up doing would make sense for LLVM, or would most of them be invalidated by the kinds of optimization passes that are common in LLVM?
E.g. stuff like making the in-memory IR representation better cacheable certainly sounds like it's all-upside, and LLVM should just learn from your project.
LLVM's use of a very rich (and hence not as memory efficient) IR is deeply rooted. Phases assume that given any value, you can trace your way to its uses, users, and owners. The LLVM code I've played with assumes this all over the place, so removing the use lists and owner links as B3 does would be super hard. B3 can do it because we started off that way.
There is a tradeoff between having a dense and compact IR and being able to modify it very easily. LLVM tends to focus on the second. Even if there are plan to balance a bit more, this will take a lot of time (and benchmarking).
>> "tl;dr: B3 will replace LLVM in the FTL JIT of webkit. LLVM isn't performing fast enough for JIT mainly because it's so memory hungry and misses optimisations that depend on javascript semantics. They got an around 5x compile time reduction and from 0% up to around 10% performance boost in general." [1]
Is this a knock on LLVM then?
I wonder then specifically if this brings to light any concerns over Swift (another dynamic language, and was created by the same person who created LLVM as well). [2]
Seems weird that the original creator of LLVM was able to make a dynamic language such as Swift - without any problems.
You're reading it too politically. It says right up in the first paragraph:
> While LLVM is an excellent optimizer, it isn’t specifically designed for the optimization challenges of dynamic languages like JavaScript.
LLVM was, more-or-less, designed around C++ semantics. B3 is not going to be a better C++ compiler than LLVM. LLVM is not going to be a better JS compiler than B3. They're taking different evolutionary paths.
Not a knock on LLVM. The conditions are just different. There is no software that is 100% great at every single thing - that's why Windows embedded CE failed while iOS and Android thrived on phone and mobile devices.
VxWorks is great at driving martian rovers, but would be horrible at running Adobe Photoshop or Maya.
Why does everything either need to be a snub or a boon?
LLVM is great at generating compiled binaries - it just takes resources (time + memory) to do so - in practical terms, the compilation time only affects the programmers and developers running multiple compiles over a work day, working on the codebase itself. For consumers who are running the programs, LLVM makes great optimized binaries.
In a JS engine, the compiler doesn't have access to the source code until a user loads up the page, so it's in essence doing "compilation" on the spot. And in this case compilation memory and time usage matters.
Swift itself is a "compiled" lanugage - meaning that in development, a developer needs to hit that "compile" button in XCode to generate a binary file which is then distributed and run. In this case, LLVM can use all cores on that big honking Mac Pro or shiny MacBook Pro 15" retina all it wants - take all 16 cpus and 32 gigs of ram and crank it and make a nice binary that comes out optimized to run on a iPad Air.
Of course things like Java conflates the two styles (source code compiled to bytecode and then to run on the JVM) - but in the Java ecosystem there are significant optimizations in both the compile phase (ie javac helloworld.java) as well as ahead of time compilation in the JVM itself.
LLVM is designed for languages that are compiled ahead of time like C and C++. In these cases it's not that important how much time and memory it takes to compile something.
If you're working on a JIT, this matters. A lot. Webkit isn't the first project has has used or worked with LLVM in this manner and abandoned it. PyPy has also investigated using LLVM and stopped doing that.
LLVM isn't bad, it just isn't good at solving this problem it wasn't designed for. If anything, I think it's remarkable LLVM has worked out as well for Webkit as it did.
Swift is generally ahead-of-time compiled, so compile speed doesn't matter as much. Many of the core parts of Swift also avoid highly dynamic semantics. The most dynamic parts are when interfacing with Objective-C classes, an area that has not been heavily optimized yet.
On the typing front, maybe you'd find this recent paper entertaining: "Is Gradual Sound Typing Dead?" (link below)
The conclusion is that it's mostly dead or worse, because of the performance hit when typechecked code calls untyped code.
(And also because of the details of Typed Racket, which perfectly reasonably translates into ordinary untyped Racket, but then that is then mangled by GNU lightning (!).)
But...
"At the same time, we are also challenged to explore how our evaluation method can be adapted to the world of micro-level gradual typing, where programmers can equip even the smallest expression with a type annotation and leave the surrounding context untouched. We conjecture that annotating complete functions or classes is an appropriate starting point for such an adaptation experiment."
Dynamic languages are (generally) not compiled ahead of time. It is possible to have static typing in a dynamic language in the sense that the code is interpreted at runtime (but the types are set statically in the code), and there is no "binary" that one runs.
It used to be called interpreted language or "scripting" language - but I think the vocabulary shifted so the word "dynamic" more encompasses what the languages are about.
It's worth noticing that most of the optimizations here are for "space" -- reducing the working set size or the number of memory accesses. CPUs have gotten much faster than memory blah blah. This is the sort of thing where microbenchmarks may mislead you, because you WSS is probably not realistic.
I think we don't have great tools for helping with this sort of optimization. One can use perf to find cache misses, but that doesn't necessarily tell the whole story, as you might blame some other piece of code for causing a miss. Maybe I should try cachegrind again...
I would say that geometric mean is the usual way of averaging benchmark scores. It has the property that a given relative speedup on a component benchmark always has the same effect on the aggregate score. With an arithmetic mean the component benchmarks with a longer runtime will dominate the aggregate. Normalizing the results before applying the arithmetic mean doesn't really help either -- the first X% improvement to a component benchmark would still be valued more than the second X% speedup.
Interestingly, much of their complaints around pointer chasing, etc, are things LLVM plans on solving in the next 6-8 months. i'm a bit surprised they never bothered to email the mailing list and say "hey guys, any plans to resolve this" before going and doing all of this work. But building new JITs is fun and shiny, so ...
LLVM instruction selection is slow, there is a "fast-path" which hasn't received much attention (it is only used for -O0 in clang). The new instruction selector work just started and will take a couple of years, considering the tradeoff between spending 3 months on it and waiting a few years for LLVM to be improved (without any guarantee of LLVM reaching the same speed as what they did).
See also some thoughts from a LLVM developer on optimizing for high-level languages: http://lists.llvm.org/pipermail/llvm-dev/2016-February/09546...
The problem with the path they've taken is it has a finite end.
This is why, when they compare it to v8/etc, it's kind of funny. They all have the same curve.
Basically all of these things, all of them, end up with roughly the same deficiencies once you cherry pick the low hanging fruit[1], and then they stall out, and get replaced a few years later when someone decides thing X can't do the job, and they need to write a new one. None of them ever get to a truly good state.
Rinse, wash, repeat.
The only thing these things make real progress, is by doing what LLVM did - someone works on it for years.
Let me quote a former colleague at IBM - "there is no secret silver bullet to really good compilers, it's just a lot of long hard work". If you keep resetting that hard work every couple years, that seems ... silly.
TL;DR If you really believe they've totally gotten everywhere they need to be in 3 months, i've got a bridge to sell you
[1] For example, good loop vectorization and SLP vectorization is hard.
Danny, you mentioned loop and SLP vectorization. One thing that bothered me while watching the development of the SLP and Loop vectorizers over the last two years was that developers who cared about SPEC added functionality that increased compile time. I remember one change that added a second phase that scans the entire IR in the SLP vectorizer to get a 1.4% win in one of the SPEC programs. I hoped the FTL project would be able to enable the vectorizers, but to my disappointment the vectorizers are too slow to justify the boost on javascript workloads.
I'm really wondering about the politics behind all this. I mean both LLVM and WebKit are Apple projects (even though they're Open Source). So it would have been reasonable to expect an improvement of LLVM instead of ditching it altogether.
I highly doubt there are any politics behind it. LLVM is an AOT C/C++ compiler at its core, and the tradeoffs it makes don't always make sense for dynamic, JIT compiled languages with extreme emphasis on compilation speed like JS. Personally, I expected this to happen.
Specialising LLVM for dynamic compilation might well come at the expense of LLVM's strengths as an AoT compiler, and it would probably not be easy in any case.
In addition to that, dedicated implementations can take various shortcuts to make their job easier - there are some nice examples given in the link. LuaJIT is example of a compiler project that benefits from being heavily specialised to a particular job, to remarkable effect.
{kind=link}
{kind=link}