This place needs more of this kind of documentation.
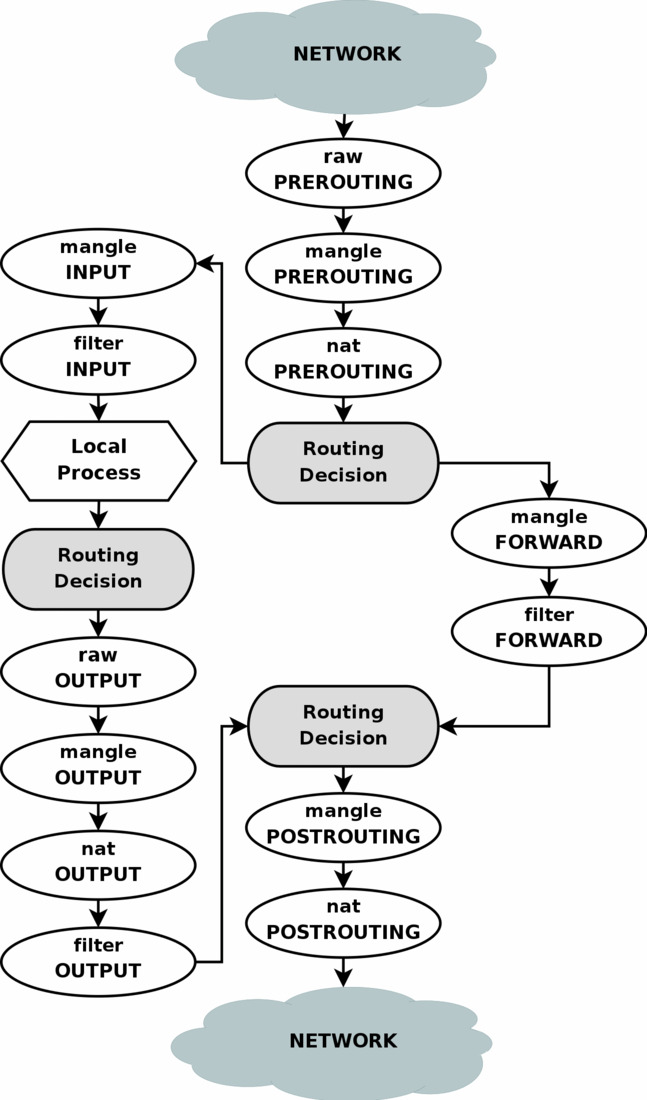
I failed to use IP tables for years. I bought books. I copied recipes from blog posts. Nothing made sense, everything I did was brittle. Until I finally found a schematic showing the flowchart of a packet through the kernel, which gives the exact order that each rule chain is applied, and where some of the sysctl values are enforced. All of a sudden, I could write rules that did exactly what I wanted, or intelligently choose between rules that have equivalent behaviors in isolation but which could have different performance implications.
After studying the schematic, every would just work on the first try. A good schematic makes a world of difference!
This also isn't complete because it doesn't show code between or around the various tables. I used to think of iptables as dumb filters that manipulate raw packets before/after the rest of the kernel sees them, but this view is wrong, and doesn't explain, for example, how it does NAT.
And the answer is it doesn't do NAT. The code is already preparing to do NAT, and that code merely consults the table to find out what kind of NAT it should do. The diagram makes it look like you can just move a NAT rule to a filter or mangle rule because the kernel just applies these tables in sequence anyway, but you can't because they are consulted by different blocks of code for different purposes.
Me too, then I discovered FreeBSD and pf tables. I _feel_ like an expert network engineer now. It took time and effort of course, but the learning process "clicked" for me all along the way and I was able to build on my understandings. Give it a try!
I've wanted to switch to nftables on some of my systems but found that some software or other depended on iptables (e.g. Docker Engine, Proxmox). Use nftables if you can get away with it but iptables-specific knowledge is still extremely relevant.
For the most part iptables is no more, iptables tools are now just wrappers to nftables. Technically you can still write iptables rules, and they will show up in nftables. Wouldnt recommend long term but its a good way to see the translation
If the author agrees, I could try to learn Serbo-Croatian (I'm Polish, good with languages) and translate it to English. I'm kinda a burnout Linux geek, who cannot look at computers much more. Translating a book would be fun, but I would need some sponsoring. Amadeusz at [the old name of icloud].com
the book is licenced under CC BY-SA so you should be OK with translating as long as you follow the licence terms.
you could try do a first pass in an AI model to translate and then proof-read it for quicker translation. good luck, it would be fun and potentially impactful ;)
To my knowledge, sadly I can't find an English version of it. I'm too wishing for a future English version so that I can read it. But I guess it will be a lot of work to translate it into English.
Thanks Hrvoje Horvat for such a detailed diagram! It'll help me learn the Network stack much, much easier.
His book "Operativni sustavi i računalne mreže - Linux u primjeni" [0] (Operating systems and computer networks - Linux in use) may well make learning Croatian worth it! Congrats on publishing, and thanks for such an invaluable contribution!
If someone could program a visualization tool that would generate such diagrams automatically, that would be even cooler (but likely a mission impossible).
Automatic generation would be really tough because of all the levels of abstraction traversed in this diagram in particular... But tools like Mermaid / PlantUML can get you in the ballpark, and PGF/TikZ could be a reasonable target if you want to attack that mission by generating text instead of images.
For containers you will also have own TCP/IP stack similarly to what is shown for VM on the diagram, this is done when a container uses slirp4netns to provide networking. An alternative is to use kernel TCP/IP stack, this is done when pasta is used for networking, diagram on this page shows the details:https://passt.top/passt/about/.
Is there some sort of equivalent to this book but in English, which explains and diagrams the Linux network stack? Doesn't need to be all in one, I feel like having a more high level overview and then subsystem diagrams with explanations would work as well.
There’s complication, and there’s complexity. Fools admire complication, engineers design solutions to complex problems. This is a diagram explaining the latter.
I think it was put pretty well by describing things as accidental complexity (of which you want as little as possible) and essential complexity, which is inherent to the problem domain that you're working with and which there is no way around for.
The same thing could sometimes fall into different categories as well - like going for a microservices architecture when you need to serve about 10'000 clients in total vs at some point actually needing to serve a lot of concurrent requests at any given time.
> inherent to the problem domain that you're working with and which there is no way around for
I'd phrase it to reasonable taken trade-offs for customer/user support and/or selling products.
> going for a microservices architecture when you need to serve about 10'000 clients
So far I am only aware of the use case to ship/release fast at cost of technical debt (non-synchronized master) of microservices.
As I understand it, this is to a large degree due to git shortcomings and no more efficient/scalable replacement solution being in sight. Or can you explain further use cases with technical necessity?
1. When you have a system where each component has significant complexity, to the point where if it was a monolith you'd have a 1M SLoC codebase that would be slow to work with - slow to compile, slow to deploy, slow to launch and would eat a lot of resources. At that point chances are that the business domain is so large that splitting up into smaller pieces wouldn't be out of the question.
2. Sometimes when you have vastly different workloads, like a bunch of parts of the system (maybe even the majority) that is just a CRUD and a small part that needs to deal with message queues, or digitally sign documents, or generate reports or do any PDF/Word/Excel/whatever processing. You could do this with a modular monolith but sometimes it's better to keep the dependencies of your project clean, especially in the case of subpar libraries that you have to use, so you at least can put all of the bullshit in one place. Also applies in cases where the load/stability of that one eccentric part is under question.
3. The tech stack might also differ a whole bunch of some of those use cases, for example if you need to process all sorts of binary data formats (e.g. satellite data) or do specific kinds of number crunching, or interact with LLMs, a lot of the time Python will be a really good solution for this, while that's not what you might be using in your stack throughout. So you might pick the right tool for the job and keep it as a separate service.
4. The good old org chart, sometimes you'll just have different teams with different approaches and will be working on different parts of the business domain - you already said that, but Conway's law is very much a thing that'd be silly to fight against all that much, because then you'd end up with an awkward monorepo, the tooling to make working which easy might just not be available to you.
{kind=link}
{kind=link}
{kind=link}
I failed to use IP tables for years. I bought books. I copied recipes from blog posts. Nothing made sense, everything I did was brittle. Until I finally found a schematic showing the flowchart of a packet through the kernel, which gives the exact order that each rule chain is applied, and where some of the sysctl values are enforced. All of a sudden, I could write rules that did exactly what I wanted, or intelligently choose between rules that have equivalent behaviors in isolation but which could have different performance implications.
After studying the schematic, every would just work on the first try. A good schematic makes a world of difference!